
阿里妹导读:云计算场景下的大规模分布式系统中,网络异常、磁盘IO异常、时钟跳变、操作系统异常乃至软件本身可能存在bugs等,均给分布式系统正确运行带来了挑战。持续的监控报警完善是打造稳定高可用分布式系统过程中非常重要的工作,这个也就要求我们研发同学从细节处入手,本文将介绍的场景是针对线上报警的一丝异常,抽丝剥茧找到内存泄露的root cause,全程48小时,跟进修复了潜在风险隐患,并进一步丰富完善监控报警体系的过程。
1、问题初现
该风险隐患在2019年10月下旬某天开始浮现,不到24小时的时间里,值班同学陆续收到多个线上电话报警,显示某业务集群中分布式协调服务进程异常:
- 14:04:28,报警显示一台Follower意外退出当前Quorum,通过选举重新加入Quorum;
- 16:06:35,报警显示一台Follower发生意外重启,守护进程拉起后,重新加入Quorum;
- 02:56:42,报警显示一台Follower发生意外重启,守护进程拉起后,重新加入Quorum;
- 12:21:04,报警显示一台Follower意外退出当前Quorum,通过选举重新加入Quorum;
- ……
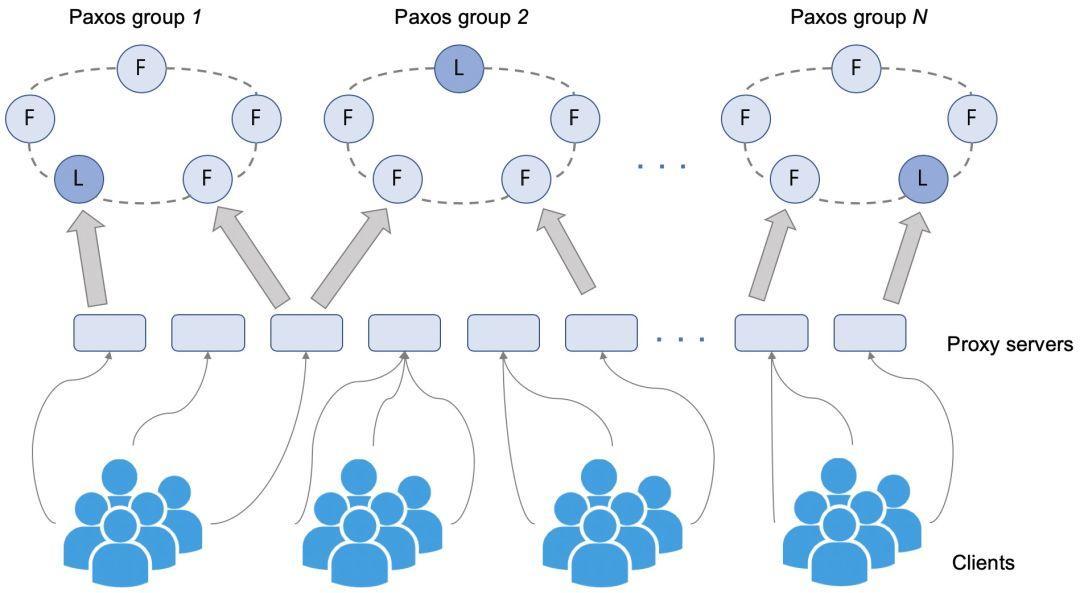
下图展示了该分布式协调服务的系统架构,后端是基于Paxos实现的一致性维护功能模块,前端代理客户端与一致性服务单元的通信,支持服务能力水平扩展性。由于后端分布式一致性服务单元由5台Master机器组成,可以容忍同时2台机器挂掉,因此上述报警均没有发现对服务可用性产生影响。但是,在短时间之内频繁发生单个Master服务进程异常,这个对于服务稳定性是个极大隐患,特别是对于作业调度强依赖分布式协调服务的某业务。由此,我们开始集中人力重点调查这个问题。
我们首先排除了网络问题,通过tsar命令查看机器上网络各项指标正常,通过内部的网络平台查看机器上联网络设备以及网络链路也均是健康状态。回到日志来分析,我们从Leader日志中找到了线索,上述报警时间点,均有“Leader主动关闭了与Follower的通信通道”这么一个事件。
很自然地,我们想知道为什么会频繁发生Leader关闭与Follower通信通道的事件,答案同样在日志中:Follower长时间没有发送请求给Leader,包括Leader发给过来的心跳包的回复,因此被Leader认定为异常Follower,进而关闭与之通信通道,将其踢出当前Quorum。
好了,现在可以直观地解释触发报警原因了:Follower长时间与Leader失联,触发了退出Quorum逻辑(如果退出Quorum过程比较慢的话,进一步会触发直接退出进程逻辑,快速恢复)。
那么新的问题来了,这些Followers为什么不回复轻量的心跳请求呢?这次没有直接的日志来解答我们的疑惑,还好,有间接信息:出问题前Follower的日志输出发生了长时间的中断(超过了触发退出Quorum的阈值),这个在对分布式协调服务有着频繁请求访问的某业务集群中几乎是不可想象的!我们更愿意相信后端进程hang住了,而不是压根没有用户请求打过来。
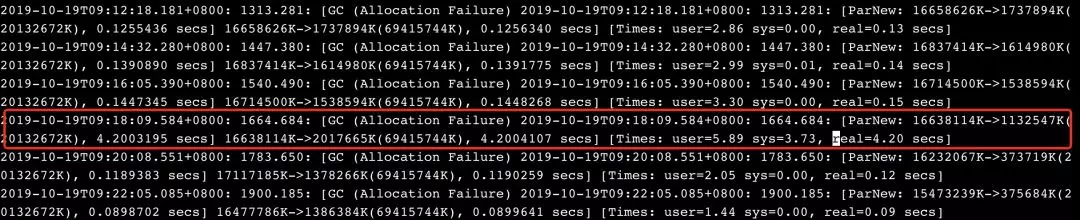
在没有其它更多调查思路的情况下,基于后端分布式一致性服务单元是基于java实现的事实,我们查看了Follower发生问题时间段的gc日志,结果找到了原因:java gc相关的ParNew耗时太久(当天日志已经被清理,下图是该机器上的类似日志),我们知道java gc过程是有个STW(Stop-The-World)机制的,除了垃圾收集器,其余线程全部挂起,这个就能够解释为什么后端Follower线程会短时hang住。
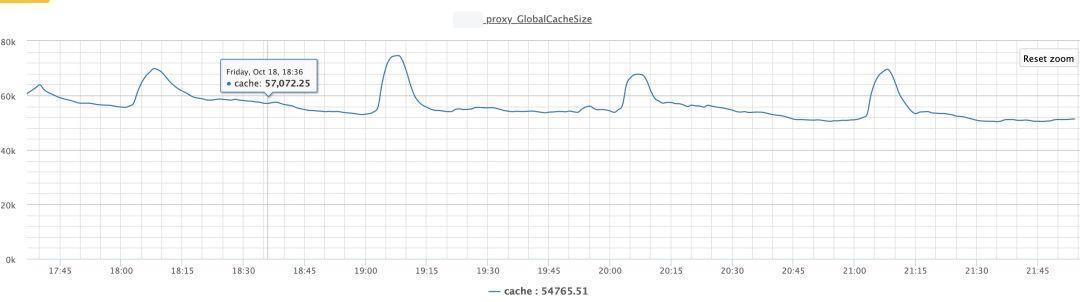
虽然我们的java程序申请的初始内存较大,但是实际分配的是虚拟内存,ParNew耗时太久一个很大可能性是机器上实际物理内存不足了。
按照这个思路,我们进一步在Follower机器上使用top命令查看进程内存占用情况,结果发现机器上混合部署的前端Proxy进程使用的内存已经达到整机66%+(此时后端一致性进程实际占用的物理内存也已经达到30%左右)。
进一步查看系统日志,发现部分机器上前端Proxy进程已经发生过因为内存不足的OOM错误而被系统KILL的事件,至此问题初步定位,我们开始转向调查前端Proxy内存泄露的问题。

2、业务风险
该业务对分布式协调服务的服务发现功能是重度依赖的。以本次调查的业务集群为例,单集群注册的服务地址数达到240K,解析地址的活跃会话数总量达到450W,因此,分布式协调服务的稳定性直接影响着集群内业务作业的健康运行。

在明确了分布式协调服务Proxy进程存在内存泄露风险之后,我们紧急巡检了线上其它集群,发现该问题并非个例。大促在即,这个风险隐患不能够留到双十一的时间点,在gcore了前端Proxy现场之后,我们做了紧急变更,逐台重启了上述风险集群的前端Proxy进程,暂且先缓解了线上风险。

3、深入调查
继续回来调查问题,我们在重启Proxy进程之前,gcore保留了现场(这里要强调一下,线上gcore一定要谨慎,特别是内存占用如此大的进程,很容易造成请求处理hang住,我们基于的考虑是该分布式协调服务的客户端是有超时重试机制的,因此可以承受一定时长的gcore操作)。
因为前端Proxy最主要的内存开销是基于订阅实现的高效地址缓存,因此,我们首先通过gdb查看了维护了缓存的unordered_map大小,结果这个大小是符合预期的(正如监控指标显示的,估算下来这个空间占用不会超过1GB),远远达不到能够撑起如此内存泄漏的地步。这点我们进一步通过strings core文件也得到了证实,string对象空间占据并不多,一时间,我们的调查陷入了困境。
这时我们想到了兄弟团队某大神的大作,介绍了在线上环境调查C/C++应用程序内存泄露问题(可能会有同学提到valgrind这个工具干嘛不用?首先这个神器在测试环境是必备的,但是终究是可能存在一些漏掉的场景发布上线了导致线上内存泄露。另外,大型项目中会暴露valgrind运行太慢的问题,甚至导致程序不能正常工作),这里提供了另一个角度来调查内存泄露:虚表。每个有虚函数的类都有个虚表,同一个类的所有对象都会指针指向同一个虚表(通常是每个对象的前8个字节),因此统计每个虚表指针出现的频度就可以知道这样的对象被分配了有多少,数量异常的话那么就存在内存泄露的可能。
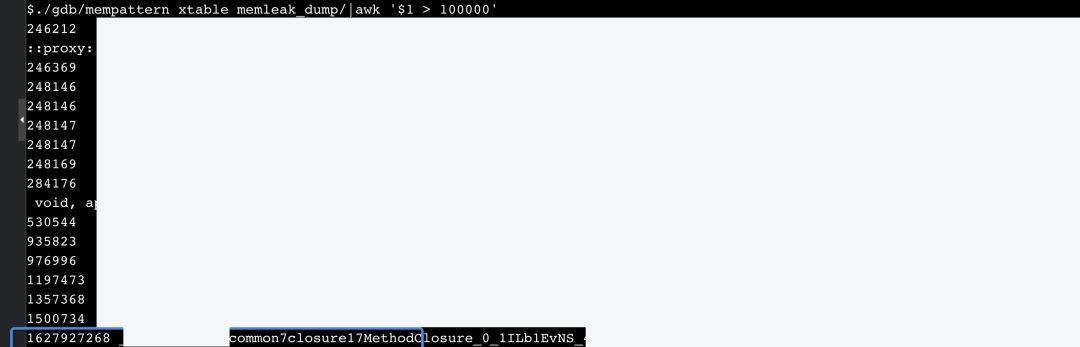
大神提供了一个内存泄露排查工具(说明一下,这个工具基于规整的tcmalloc的内存管理方式来分析的),通过符号表找到每个vtable,因此可以知道虚表地址,即每个虚函数类的对象前8字节的内容,这个工具厉害的地方在于摆脱了gdb依赖,直接根据应用程序申请的所有内存块分析,找到所有泄露内存块地址,进一步统计出每个虚表对应类的对象数目。具体这个工具实现细节不再赘述,最终我们统计出来的所有出现频率超过10W的虚表信息,找到了罪魁祸首:这个common::closure的对象泄露了高达16亿+。
根据closure的参数类型信息,我们很快定位到了具体的类CheckCall:
$grep Closure -r proxy | grep Env
proxy/io_handler.h: typedef common::Closure<void, Env*> CheckCall;
有关这个对象的大面积泄露,定位到最终原因其实是跟我们对Proxy日志分析有关,我们在日志中发现了大量非法访问请求:客户端尝试解析某个角色注册的服务地址,但是却使用错误的集群名参数。在单个Proxy机器上1s时间里最多刷出4000+这样的错误日志,那么会不会是因为持续走到这样错误路径导致的对象内存泄露呢?

对照这块的代码,我们仔细研究了一下,果然,CheckCall对象正常是会走到执行逻辑的(common::closure在执行之后自动会析构掉,释放内存),但是在异常路径下,譬如上面的非法集群名,那么这个函数会直接return掉,相应的CheckCall对象不会被析构,随着业务持续访问,也就持续产生内存泄露。
4、风险修复
这个问题的rootcause定位之后,摆在我们面前的修复方法有两个:
1)业务方停止错误访问行为,避免分布式协调服务前端Proxy持续走到错误路径,触发内存泄露;
2)从前端Proxy代码层面彻底修复掉这个bug,然后对线上分布式协调服务Proxy做一轮升级;
方案二的动静比较大,大促之前已经没有足够的升级、灰度窗口,最终我们选择了方案一,根据日志中持续出现的这个非法访问路径,我们联系了业务方,协助调查确认业务哪些客户端进程在使用错误集群名访问分布式协调服务,进一步找到了原因。最终业务方通过紧急上线hotfix,消除了错误集群名的访问行为,该业务线分布式协调服务前端Proxy进程内存泄露趋势因此得以控制,风险解除。

当然,根本的修复方式还是要从前端Proxy针对CheckCall的异常路径下的处理,我们的修复方式是遵循函数实现单一出口原则,在异常路径下也同样执行该closure,在执行逻辑里面判断错误码直接return,即不执行实际的CheckCall逻辑,只触发自我析构的行为。该修复在双十一之后将发布上线。
5、问题小结
稳定性工作需要从细节处入手,需要我们针对线上服务的每一条报警或者是服务指标的一丝异常,能够追根溯源,找到root cause,并持续跟进风险修复,这样一定可以锤炼出更加稳定的分布式系统。“路漫漫其修远兮,吾将上下而求索”,与诸君共勉。
原文发布时间:2019-12-20
作者:朱云锋
本文来自阿里云合作伙伴“阿里技术”,了解相关信息可以关注“阿里技术”。


网友评论