时间: 2021-07-30 09:15:59 人气: 7 评论: 0

数据仓库是存放收集来的数据的地方,数据仓库的特征有按时抽取、分层存储、切**存储、抽建模业务等。
数据产品的工作比较杂,从数据仓库建模,指标体系建立,到数据产品工具的设计,再到偶尔一些数据分析报告的撰写,甚至一些机器学习的预测模型都要有所了解。大公司可能每个职能都有专门的岗位来负责,小公司的话可能真的要你一条龙了。
其实数据产品从头到尾做的事情就是帮公司收集数据、存储数据、呈现数据、预测数据,拆分到具体的工作中,将**在下面介绍。
数据仓库是存放收集来的数据的地方,做数据分析现在一般尽量不在业务数据上直接取数,因为对业务数据库的压力太大,影响线上业务的稳定。
数据仓库里的数据按照数据收集的时间间隔大致分为两类:
对于第一类一般的处理多数要求在“天”级别,比如说:一天从业务数据库更新一次数据就足够了,一般采用MapReduce等批处理框架来处理数据,批处理框架在进行大量数据的计算的时候有计算资源比较廉价等优势。
而第二类实时数据处理,需要采用一些流处理框架,例如:Storm、Spark等,来处理数据,当业务发展到一定阶段,业务人员对数据的实时性要求**越来越高,也就对大数据技术团队提出了更高的要求,当然实时处理数据所需要付出的代价也是更高的。
我们要分辨清楚,哪些数据采用批处理就可以了,哪些数据是有实时处理的价值的,并不是说所有数据都实时处理就是更好,毕竟集群资源是有限的,要合理利用计算资源。
另外数据仓库的数据存储是分层级的,这个架构一方面跟数据拉取方式有关,一方面也是为了对数据进行层级的抽象处理。
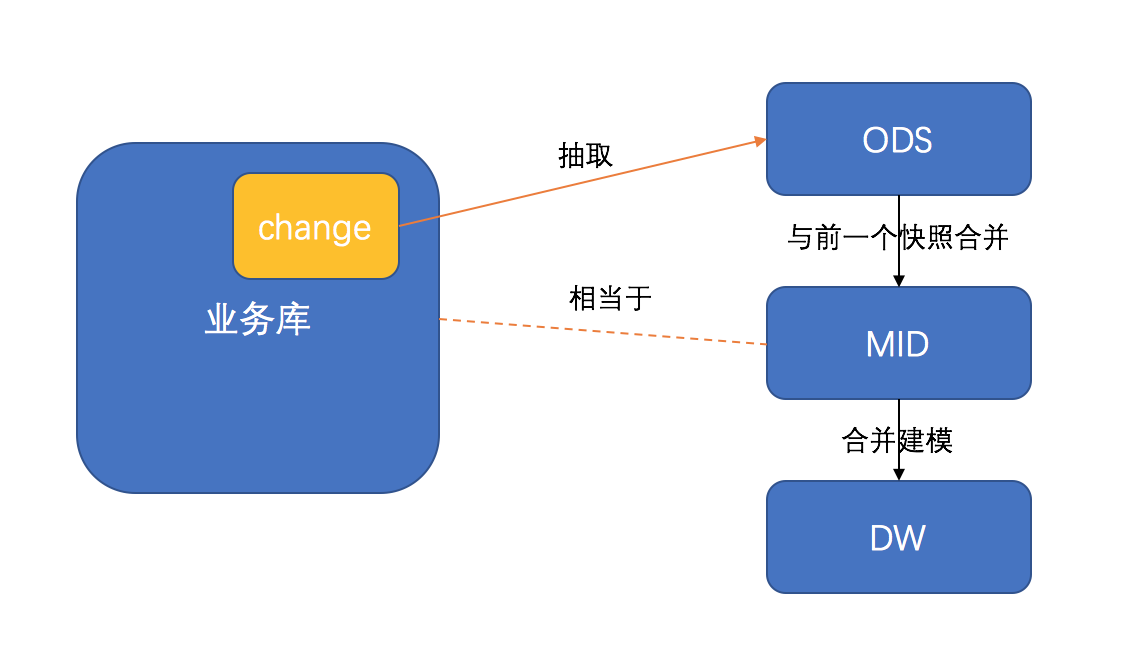
一般来说数据仓库**至少分为ODS、MID、DW三个层级,当然层级的名称每个公司可能不同,这里主要是在作用上进行区分解释。
因为MID层和DW层存储的都是完整的数据,业务数据库数据**不断增长,导致这两个层级里的数据每个切**的数据都是在增长,相当于是指数增长。
数据库的存储是分时间戳的,相当于是把数据按照快照的方式存了n个版本,当你想追溯在某天某时间的数据的时候,就可以通过定位特定的时间戳,追溯到相关的数据。
这种设计避免了业务库数据**不断覆盖的问题,相当于是在数据分析的时候加了一个时间维度,提升了一个维度,看问题解决问题的角度也就被升华了。
MID层向DW层抽象的过程,需要数据产品对业务库表进行建模。首先要清楚了解,你所要进行抽象的业务系统是什么样的(感觉数据产品好累,还要去了解别人的系统是怎么玩的╮(╯_╰)╭)。
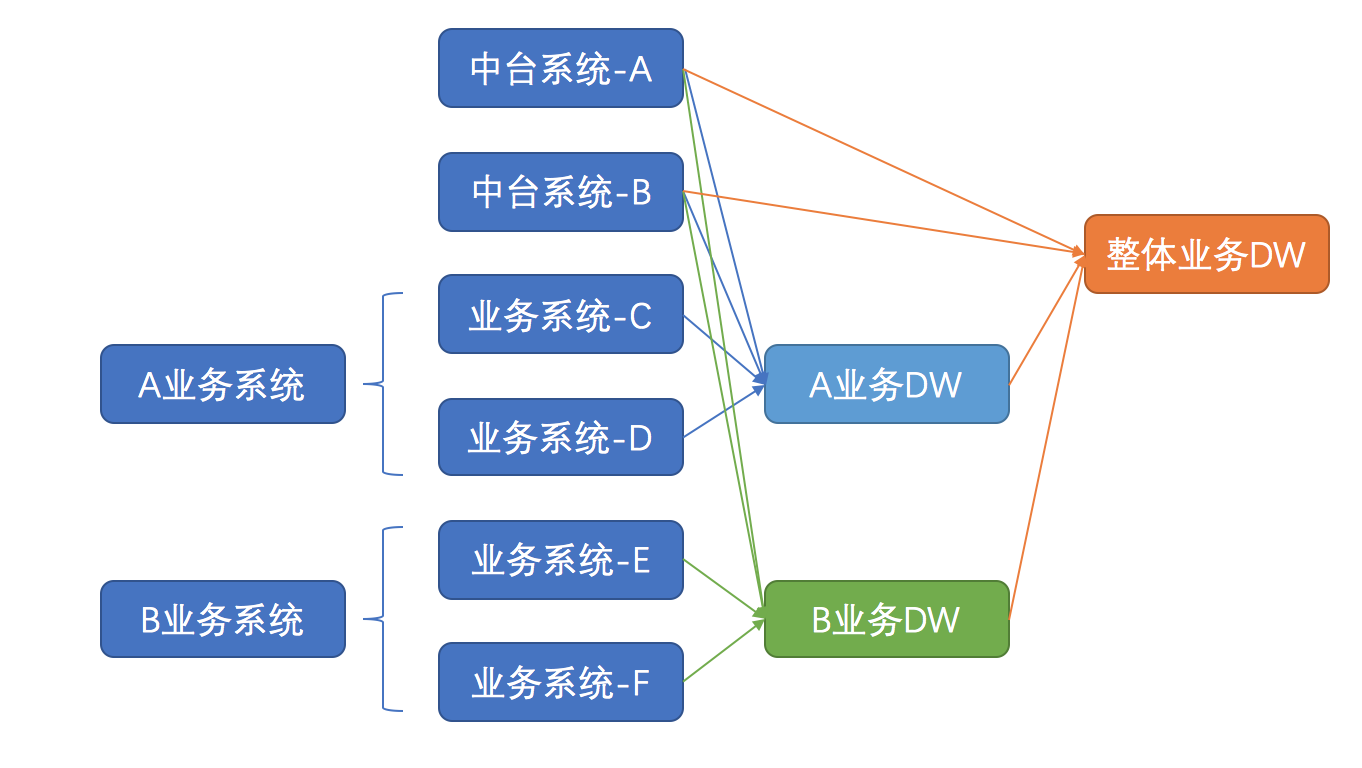
比如:你所要负责的是A业务系统的DW设计,那么首先你要把A业务系统的系统逻辑搞清楚,然后它所涉及的库表都了解清楚,包括业务本身的库表以及它所依赖的中后台系统的库表,以及各个数据库之间的关系是怎样,比如:是一对一还是一对多,当前库表是否是最细粒度的数据。
一般来说建模要做到模块互相独立,粒度统一。因为考虑到后期做指标和取数的方便,在不同粒度上都有表是比较好的。
比如:一个电商分期业务,可能在订单粒度上才能取到放款等数据,但是品类等维度又只能在商品粒度上取到(考虑到购物车,一个订单可能对应多个商品),这时候就需要两个粒度都建立对应的表才能满足不同的取数需求。
作者:小九,一枚互金数据产品
本文由 @小九 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pexels,基于 CC0 协议
