时间: 2021-07-30 09:20:20 人气: 16 评论: 0

刚哥风趣幽默,以一个硕大无比的搪瓷缸闻名。刚哥懂历史,也晓风月,更关键的是:他是A/B测试界里最懂统计学的;统计学界里A/B测试实战经验最为丰富的老兵。本文是浓缩了刚哥多年行业经验与A/B测试的精髓,涨知识走起!
刚哥声名在外,记得刚到公司第一周,见他用一套《A/B测试与统计学300题》虐遍了整个公司(哦,不,刚哥说30题就够虐了)。后来有幸跟刚哥交流,他端起了标志性的搪瓷缸。

抿口水,语重心长地对我说:“小张,你以为我是故意要虐大家吗?身为咱们数据分析人,懂A/B测试与统计学是我们的基本修养呀。”我听后,深以为然,对刚哥的崇敬愈深。
后来需要刚哥交一篇关于A/B测试的文章,他笔下生花,交出了这份浓缩着多年行业经验与A/B测试精髓的帖子。
从总体中随机抽取一个容量为n的样本,当样本容量 n足够大(通常要求n ≥30)时,无论总体是否符合正态分布,样本均值都**趋于正态分布。期望和总体相同,方差为总体的1/n。这即是中心极限定理,是A/B测试数据分析的基础。
然而抽样分为有放回和无放回两种。样本均值的方差是总体方差的1/n(n为样本容量),这个结论是针对有放回抽样的。实际试验中,大部分是无放回的,这样流程比较简单。无放回抽样,样本均值方差见下。观察公式可知道,当总体容量比样本容量大很多倍时,样本均值的方差可以近似为总体方差的1/n。
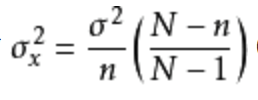
当两个样本的获取存在关联时,称为配对样本。例如比较人早晚身高变化,如果早上身高的样本包含了张三,则晚上身高的样本也要包含张三。
某些情况下配对样本比较难实现,比如药物双盲试验,患者不能既服用安慰剂又服用药物。这时只能使用独立样本,随机分配个体进入两个样本,认为2个样本的个体统计上不存在差别。同时患者不知道自己服用的是安慰剂还是药物,消除心理作用的影响。
互联网产品的A/B测试和新药试验类似,**上说应该让同一组用户同时看到多个版本进行比较,或者是看完一个版本后用时间机器倒回去再看另一个版本。显然无法做到,只能选取试验用户时足够的随机,让两组用户从统计意义上相同,认为偏差都是产品版本造成的。
A/B测试计算置信区间的公式:
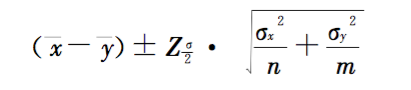
置信区间计算公式中的方差项,**上应该使用总体方差。而总体方差没法知道,只能用样本方差来代替了。好在样本方差是总体方差的无偏估计。样本方差和总体方差的比值,符合χ2分布。
A/B测试需要假设产品用户的访问习惯不**随着时间的推移而发生变化。很遗憾在某些情况下并不是这样。某些产品存在很明显的季节因素,例如旅游。一般的A/B测试周期**包含休息日和工作日,但很难包含多个季节,在外推测试结论时要十分谨慎。另外,强烈的外部事件**对用户产生刺激,要避免在这种情况下进行A/B测试,尽量在平稳时期进行。
A/B测试里犯错不可怕,可怕的是不知道自己犯错了。
P-value 是根据统计数据计算得来的,多次试验的话**得到不同的 P-value ,究竟哪个值才是犯第一类错误的概率呢?所以, P-value 和犯第一类错误的概率无关。犯第一类错误的概率应该只和实验系统有关,是在开始试验之前就知道的,显著性检验标准 α 才是犯第一类错误的概率。显著性检验标准 α 是试验者设置的,作为试验者可以有效的控制犯第一类错误的概率,是不是更加合理呢?
95%置信区间为[x,y]意味着被估计参数有95%可能属于区间[x,y],且在区间中间的概率更高一些。
传统的假设检验基于频率学派。对于频率学派来说被估计的参数没有不确定性,它就是一个固定的值。有不确定性的是抽样,是试验数据,所以95%置信区间真实的意思是做100次试验,得到100个区间,其中有95个区间能包含被估计参数的值,[x,y]只是众多区间中的一个而已,下次试验得出的置信区间就不是它了。
P-value 是当原假设为真时,得到比目前更加极端试验数据的概率。P-value 无法描述原假设成立的概率,因为对于频率学派来说原假设是否成立是不存在不确定性的。频率学派在进行试验前对所有的原假设一视同仁,先验知识无用武之地。实际情况下,我们对不同原假设的信心显然是不同的。所以同样是 P-value 为0.01,如果试验用来证实增大网页上的一个按钮能提高点击率,产品经理**欣然接受,如果试验想推翻动量守恒定律,根本不**有人正眼看一下这个结果。
一般进行A/B测试时,**先做小流量试验,之后逐渐增大。这是业界常规的做法。需要注意的是,在均值数据仅根据 UV 平均没有进行天数平均的情况下,新进入的流量**拉低均值数据。这很好理解,新进入试验用户贡献的点击量必然不如已经进入试验若干天的用户。如果各试验版本的流量是同步放大的,这种新用户效应对不同试验版本统计数据的影响是相同的。如果流量放大不同步,比如一个试验版本5%-10%,另一个试验版本5%-20%,后一个版本的均值数据**受到更大的拖累。对于转化率指标,情况**好不少,因为一个用户最多贡献一个转化,最先进入试验的用户对指标的贡献不**比新用户更大。
在A/B测试之前进行A/A测试,避免工具有 bug ,这也是业界常规的做法。预期的结果当然是统计不显著。然而,犯第一类错误的概率总是存在的,无论多么小。在一次试验中,小概率事件几乎不**发生;不停试验,小概率事件几乎一定**遇到。A/A测试中偶然出现的统计显著结果并不能断定测试工具存在 bug ,可能仅是概率使然。
A/B测试是通过给相同的用户群体看不同的版本,来进行比较,最大程度的保证结果的科学性和准确性。这是由随机分配流量来保证的,而试验者人为的进行流量分配,给不同来源的用户看不同的版本,则比较结果可能**不准确。如果最终目的就是想让2个来源的用户看到不同的版本。则建立2个定向试验,分别进行验证,如果确实胜出的版本不同,结束试验后,由前端程序把这种个性化方案固定下来。A/B测试的目的是测试,测试总有结束的一天,测试结束后去掉测试代码,把胜出方案固定下来,通过A/B测试平台来实现产品功能是不合适的。
作者:刚哥@吆喝科技(微信:appadhoc)数据分析老兵,统计学专家
本文由 @ 刚哥 原创发布于人人都是产品经理。未经许可,禁止转载。
