时间: 2021-07-30 09:27:26 人气: 11 评论: 0
研究者通过卡**分类对参与者的习惯、偏好进行调查,并可以由此了解到用户的归类原因以及价值观。

卡**分类是一种简单易行的信息整理工具,它将信息系统中的元素组织得让用户易于理解,用于帮助设计或者评估信息架构,通常在用户研究与设计初期执行。邀请用户参与可以真正了解符合用户习惯的信息架构。研究者通过使用标有单词、图**的若干主题卡,鼓励参与者按他们的偏好顺序对其进行整理归类。卡**分类可以帮助研究者获得诸多洞察,甚至可以在卡**分类后进行深入的对话,了解他们归类的原因、价值观。
开放式卡**分类:给定待分类的主题卡。参与者根据他们的理解将主题卡聚合成若干组别,并以他们描述内容的方式命名组别。
封闭式卡**分类:给定待分类的主题卡和组别,参与者根据他们理解将主题卡划入既定的组别。
一对一执行:配备一名可用性团队成员,参与者独立执行。这样可以更深入地了解参与者的思考过程,但耗时较长。
一对多执行:配备一名可用性团队成员,各参与者独立执行。这样可以快速收集多份分类,但需要准备更多的材料,同时对每位参与者的了解不深。
团队共同执行:配备一名可用性团队成员,各参与者共同执行。协作可以更快地完成分类,但需要将团体动力学考虑进去,如群体气氛、群体成员间的关系、领导作风对群体性质的影响。
远程执行:不需要配备可用性团体成员,参与者各自执行。这样可以跨地区执行,但无法了解参与者思考的过程。
邀请用户参与卡**分类测试,有助于了解站在用户的角度来理解信息的组织。了解用户整理归类的方式可以帮助产品团队验证分类是否符合用户预期,并进一步优化信息架构。
主题卡:根据需要测试的主题准备单词主题卡或图**主题卡,每张卡**只有一个主题。通常数量在 50 至 60 ,过量容易造成参与者疲劳。
空白卡:准备若干空白卡,以便参与者自行添加主题。
组别卡:考虑使用不同于空白卡的组别卡,让参与者为组别命名。
主题卡编号:考虑在不明显的地方编号,以便于后续研究者进行分析。
邀请用户:相关实验表明,15 个样本量得出来的分类结果与全部用户的分类结果之间的相关系数达到 0.90 。查看报告
估算时间:提供估算时间有助于参与者建立完成时的预期。
足够空间:以便参与者将主题卡平铺在在桌上或者粘贴在墙上。
随时记录:可用性团队成员可以随时记录参与者的想法、理由或挫折。
准备奖励:如果合适,为参与者准备若干小奖品。
说明目的:向参与者简要说明本次开放式、封闭式卡**分类的目的。在开放式中,请说明要求参与者针对自定义的组别命名;在封闭式中,请说明想要了解参与者如何定义这些组别。
随机演示:随机出现的卡**有助于参与者进行分类。
执行分类:尽量不要打断参与者。并允许参与者使用空白卡添加主题,或弃置不想要的主题卡。
大声思考:鼓励参与者大声思考,有助于可用性团队成员随时记录。
提供奖励:如果合适,为参与者提供若干小奖品。
及时记录:及时拍摄分好类的主题卡,记录分组的名称、数量以及主题卡。为下一次测试重新洗牌。
有很多桌面工具、在线工具可以执行卡**分类,且多数工具都具备基本的分析能力,以下是较为常见的工具:Cart Sort(Windows 应用程序)、xSort(Mac 应用程序)、OptimalSort、UsabilityTest Card Sorting 等。
通过测量所有卡**两两之间的距离,来研究它们之间的相似性。故可以使用任何研究距离矩阵的标准统计方法,如层级聚类分析(hierarchical cluster analysis)、多维标度法(multidimensional scaling)。
在数学中, 一个距离矩阵是一个包含一组点两两之间距离的矩阵(即二维数组)。因此给定 N 个欧几里得空间中的点,其距离矩阵就是一个非负实数作为元素的 N × N 的对称矩阵。
——维基百科
(1)Donna Spencer’s Card Sort Analysis Spreadsheets
Donna 的模板提供了 20 * 200 以及 40 * 400 的联动数据表 。除此之外,Donna 的模板还在数据表中提供了标准化的处理。
(2)SPSS Statistics
很多商业统计工具可以实现,包括 Excel 在 Windows 上的插件 Unistat 。下面以SPSS 的操作分层聚类分析的路径为例。
路径:SPSS – Analyze – Classify – Hierarchical Cluster
(1)将每位参与者的数据转成 N * N 的对称矩阵
根据不同的定义,在录入数据的时候有两种预处理思路,但异曲同工:
以共生矩阵为例,设定单个参与者放置在同一组的卡**之间距离为 1 ,录入参与者的卡**分组,可以得到一张这样的矩阵——矩阵中的距离只能是 1 或者 0 。
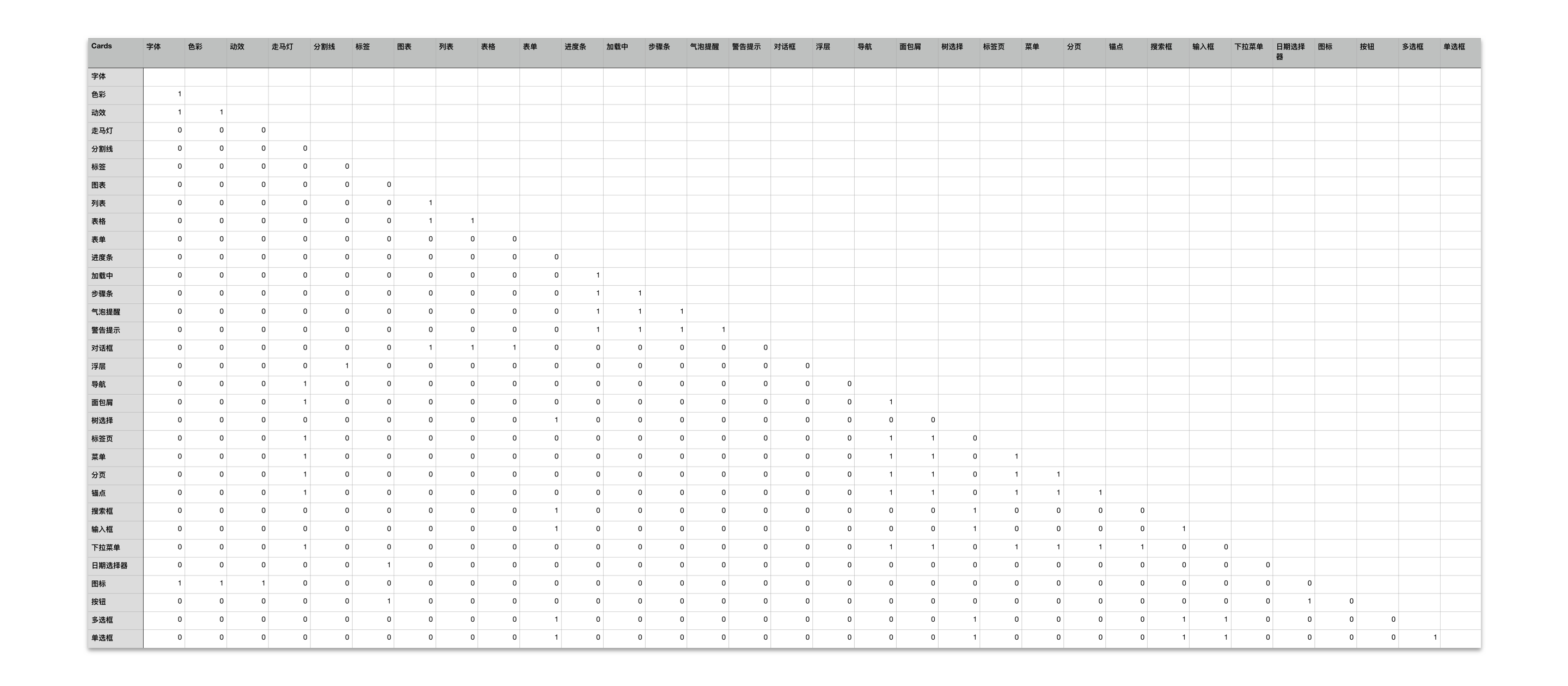
(2)将所有参与者的 N * N 对称矩阵叠加
叠加之后的对称矩阵可以看到两两卡**被放到一组的频次。因分析数据的需要,需要补齐完整的矩阵,包括对角线。
以共生矩阵为例,所有参与者的对称矩阵如下: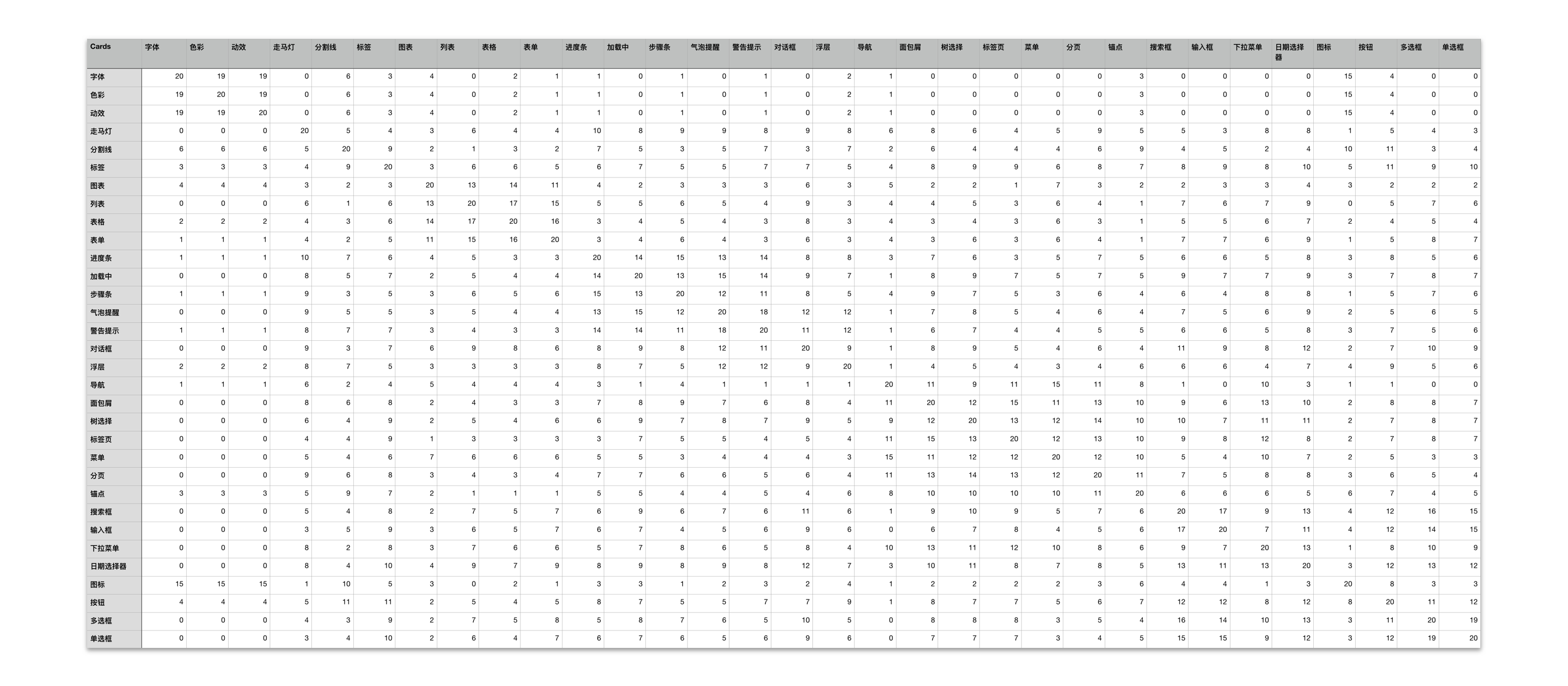
(3)调整数据格式
在变量视图里面,将卡**名调整为定类变量,将卡**频次调整为定距变量。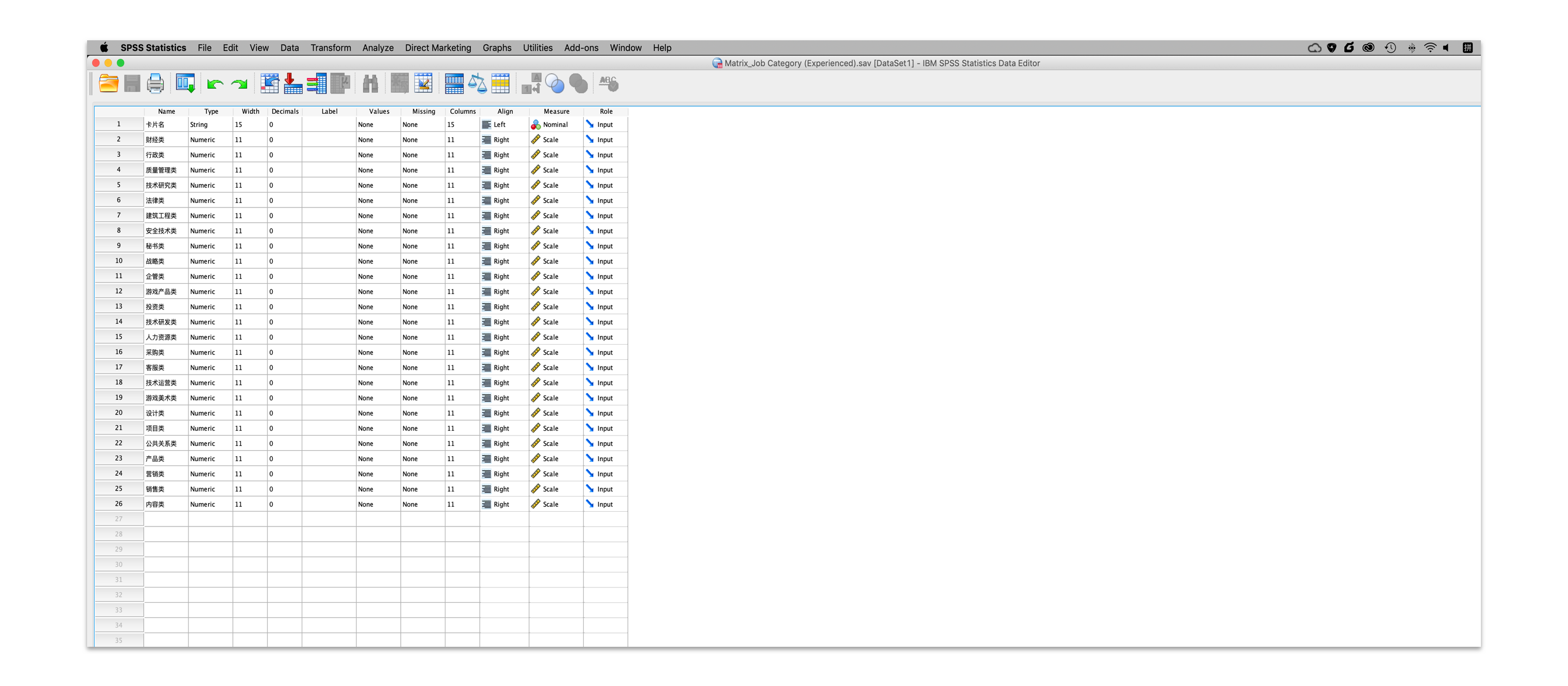
(4)层级聚类分析
在使用 SPSS 运行层级聚类分析时,可以使用不同的联接方法和度量距离进行运算。根据经验,Between-Groups Linkage(组间联接法)、Within-Groups Linkage(组内联接法) 以及Ward’s Method(Ward法)是比较行之有效的连接方法;同时,由于我们是对观察记录(cases) 进行分类,在选取度量区间上使用 Q 型聚类的 Euclidean distance(欧氏距离) 或 Squared Euclidean distance(欧氏距离平方)。
联接方法:
度量区间:
从冰柱图(Vertical Icicle)和系统树图(Dendrogram)查看分类结果。
(1)冰柱图怎么看
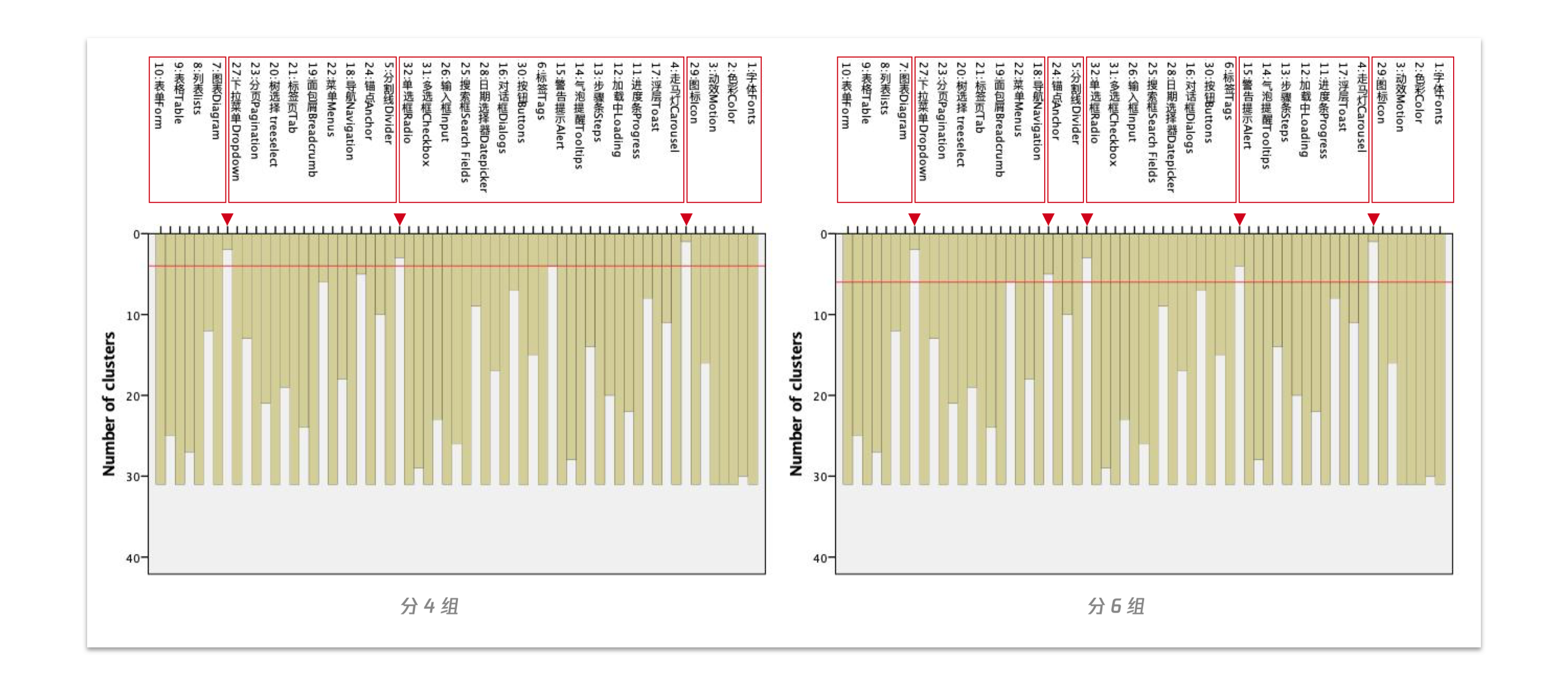
(2)系统树图怎么看
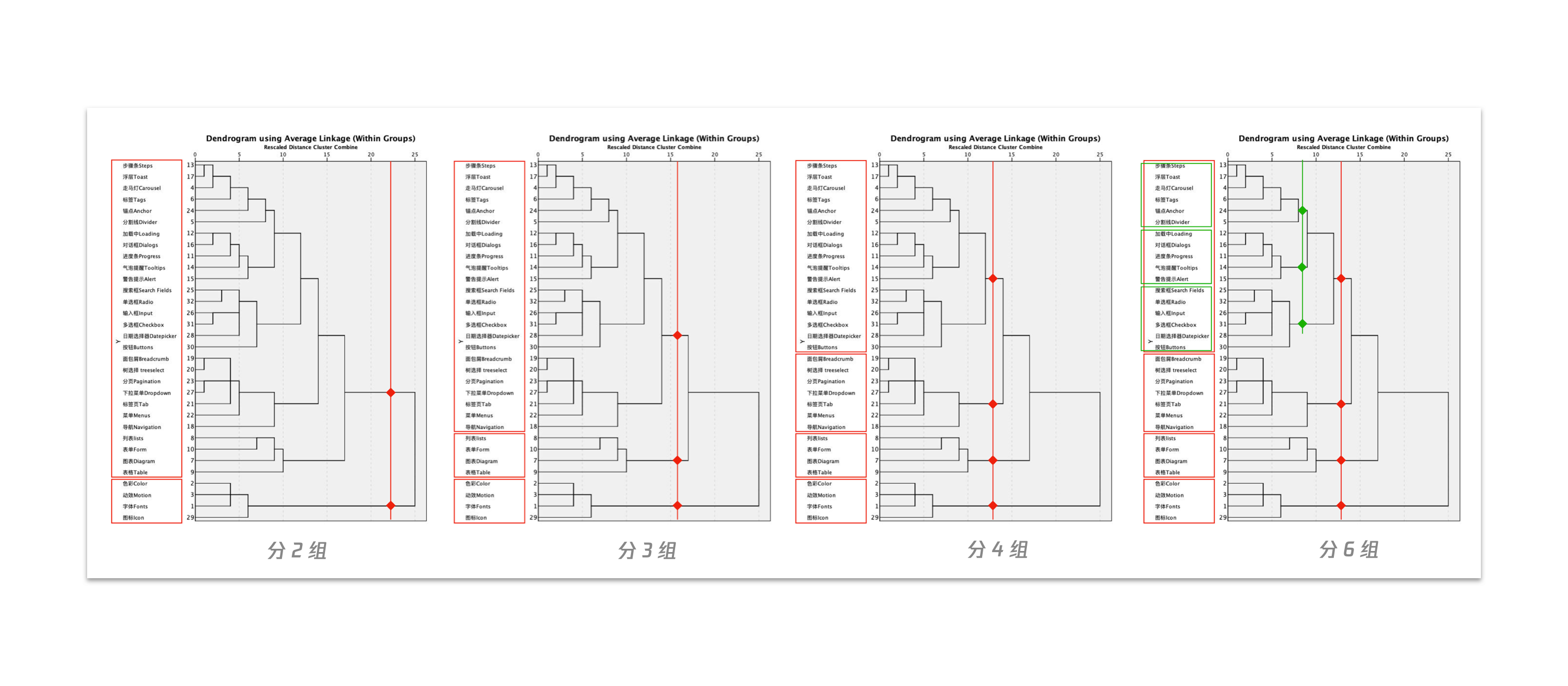
通常,一个开放式卡**分类后,可以紧跟一个或多个封闭式卡**分类,通过封闭式卡**分类来验证信息归类是否合适。
定义衡量指标为把主题卡放置各组别中的参与者比例。每张主题卡在组间比例悬殊较大的,是较有把握的分类;反之,是存在分歧的分类。
使用 Excel 就可以完成基础统计。
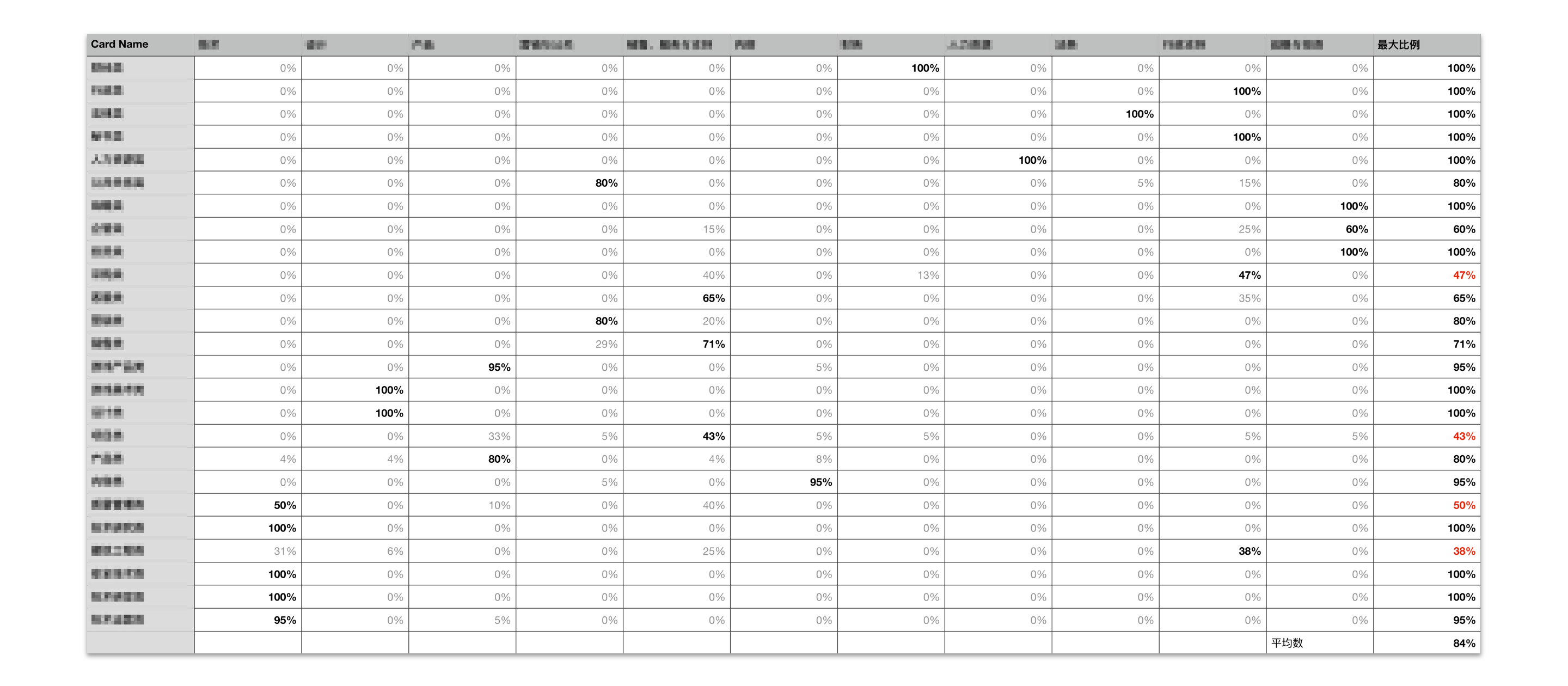
当我们列举了多种分类方式,需要验证求其一时,则需要基于每种分类方式,邀请数量一致的不同参与者。同时需要考虑:
写在最后的一些经验:
(1)主题卡编号提高录入效率。将线下数据转录至线上是一个量大效率低的事,结合卡**编号可以有效提高录入效率。
(2)主题卡的措辞尽量精准,避免偏差、歧义。无法避免时,可以在主题卡上加以解释。否则难以理解的主题卡**被用户分到无法解释的类别。
(3)用户的结果不一定是合适的。在主题卡涉及领域较广且主题卡理解有不可避免的偏差时,目标用户的分类受知识所限,可以考虑专家法,执行封闭式卡**分类。
作者:Shia
来源:Tencent CDC(https://cdc.tencent.com/2019/03/28/解锁卡**分类全过程/)
本文来源于人人都是产品经理合作媒体@**CDC
题图来自Unsplash, 基于CC0协议
