时间: 2021-07-30 09:31:29 人气: 9 评论: 0

文章分享的主要内容为用户画像要如何建模,希望本文对你有所帮助。
用户画像最终的结果是一张大宽表,一行为一个用户的用户画像,存储了用户对应的每个标签值。建模就是为每个标签制定合理的计算公式。

(请点击查看大图)
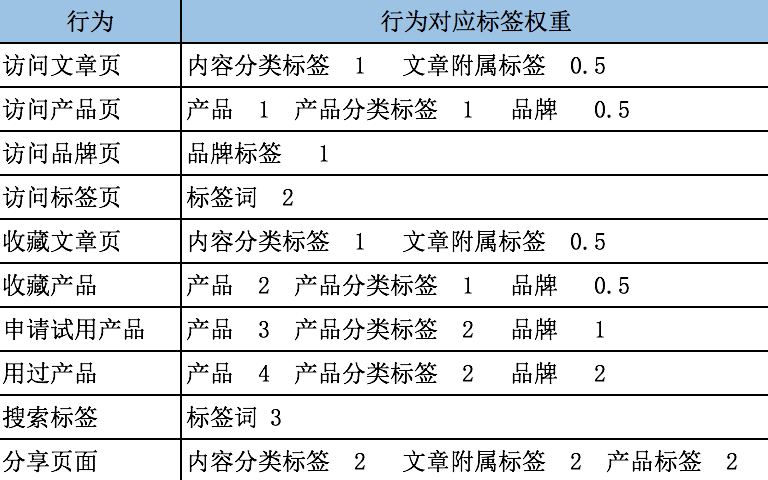
基础数据一般有用户数据、内容实体数据、用户行为数据三类,需要根据用户行为构建相应的数据模型产出标签和权重。每一次的用户行为,可以详细描述为:什么用户,在什么时间,什么地点,发生了什么事。
从上述建模方法中,我们可以简单勾画出一个用户行为的标签权重公式:
标签权重=时间衰减(何时)x网址权重(何地)x行为权重(做什么)
如果是访问行为,可以再增加访问时长的权重,10S以内权重为1,10S-30S为2,30S以上为3
最后把用户一段时间内同一个标签的权重进行累加,就获得到用户此标签的值。
根据行为的成本大小来判断标签的权重,成本越高越是真爱。例如访问页面是成本最小的,同时赋予标签的权重值就较低收藏能代表用户的喜好,权重较高。
此外这里我们假设同一个页面所附属标签和页面内容的相关度都是一样的,例如一篇文章《女人懂西装是一件很性感的事 你的他穿对了吗》附带了男装、高级定制、时尚、潮流、西装 5个不同标签,其实内容和标签的相关度**有差异,可以通过编辑人工或者机器学习的方式为标签赋予不同的相关度,这样最终得出的标签权重可信度更高。
以上只是基础模型,适用于内容标签、产品分类、产品标签、品牌标签。美妆总体偏好度、用户活跃度、用户价值等标签仍需要单独建立模型。潜在需求的挖掘适用回归预测等算法模型。
内容偏好度(美妆、服饰)模型
用某分类下所有标签的累加值来度量用户对内容的总体偏好度,例如:用户A的美妆偏好度为其所有美妆类标签值的加和。如果服饰总体偏好度大于美妆偏好度,说明用户访问的服饰内容较多,在本站内更偏向看服饰内容。
活跃度可以根据用户来访、互动情况、核心功能使用频率等综合确定。例如:
消费领域最广泛应用的是RFM模型。
计算结果为:543,代表R5F4M3级别对用户,根据产品类型的不同,可以调整R、F、M的定义。
借鉴RFM模型的思想,我们可以把用户行为也拆解为三个维度来衡量:最近访问时间、访问频次 、互动次数;(只是一种想法,未经实践检验)
最后简单说下需要预测的标签模型,预测更多是推荐系统要做的事情,类似潜在需求的标签需要用到机器学习算法,根据用户标签权重、收藏了产品A、产品C、产品D的用户,挖掘还喜欢哪些产品和内容。比较常见的有贝叶斯、回归算法。
作者:百川,微信公众号:修炼大数据(studybigdata)
本文由 @百川 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自PEXELS,基于CC0协议
