时间: 2021-07-30 09:32:19 人气: 10 评论: 0

本例仅仅是基于调研目的灵活处理的一个例子,适合短平快的项目;如果需要系统了解用户,深入挖掘用户需求,更大的样本量和更扎实的定性研究依然是必不可少的。
现代商业离不开对用户的理解,任何业务的决策者都不**希望在认识用户上存在盲区,因此在用研的日常工作中,“做一个用户画像”是经常收到的需求。但同样的需求背后,往往对应着不同的目标和问题,搞清楚了解用户能帮助业务方解决什么问题,才能更有效地制定研究方案。大而全的数据平台,不一定可以和粒度很细的调研目标精确匹配;传统市场调研或设计调研的方法又**增加周期和成本,不适合短平快的项目。那么是否可以使用简单的测量-统计方法,较敏捷地得到一个需求方期望的“用户画像”呢?本文来分享这样一个案例。
在接手话题版块改版方向调研的过程中,其中一项调研目标比较有意思:运营同学发现,网易新闻客户端话题版块中,一些女性相关话题活跃度格外高,这与对目标用户的预期有一些偏差。依照大家的印象,新闻客户端中壮年男性比例偏高,典型用户是一个体制内老刘的形象-时政、社**、历史、军事版块的重度读者-因此在话题运营上也更偏向了此类内容。然而偶尔为之的母婴、情感类的话题,无论从参与热度还是质量来考量,效果都不错。运营同学陷入思考之中,怀疑话题版块活跃着一些假的网易新闻用户。
那么话题社区的活跃用户真的与客户端整体不同吗?运营同学由此提出了调研需求,希望了解话题活跃用户的“性别、年龄、婚姻状况。。”等等的一揽子人口学变量描述,简言之-“做一个话题版块的用户画像”。
不管如何做,先梳理一下需求,把目标拆解成回答以下两个问题:
大家可能注意到,需求方在提需求的时候,顺带提了一下自己对用户区分维度的界定“性别、年龄、婚姻状况。。”。诚然,人口学变量用来区分用户很经典,但并不适用于所有研究目标,比如在本例中的效果就未必好。原因有二。首先,人口学变量并不直接能落地到业务,还需要基于业务理解进行二次推演,不够直观;而好的分类标准应该能直接与现有资源结合来指导业务;二是完全无预设的情况下,事前很难确定各个人口学变量的影响权重,那么如果需要进行探索性分析,需要在问题中纳入足够多的变量。这样短短问卷难以承载,也**让分析头绪无端变多。
所以研究用了另一个解决方案,直接用内容偏好特征来区分用户。这样做的好处是,作为内容分发平台,直接以内容偏好为标签的用户画像天然具有可落地的属性,而不必再通过人口学特征去推断。另外,对内容的需求偏好往往反映了一个人当前的综合状态-社**经济地位、文化倾向、人口学特征-可以预期是一个很有效的探测点。
相关的问题设计很简单,只是在问卷结尾处加一道内容偏好的多选,备选项参考了主流新闻app的版块分类。
您平时使用网易新闻客户端时,喜欢看哪些内容?(多选)
- 科技互联网、数码IT
- 体育赛事、运动健身
- 财经金融、投资理财
- 时事要闻
- 母婴亲子
- 情感两性
- 时尚美妆
- 娱乐明星
- 动物萌图
- 游戏动漫、二次元
- 影视音乐、摄影旅行
- 健康医疗、营养养生
- 社**民生、房产资讯
- 汽车知识
- 国际政治局势
- 历史掌故、军事动态
- 神跟贴、幽默段子
- 星座命理
- 其他(请注明)
这里有个问题简单说明一下-为什么要把选项切到这么碎,而不加以合并。这种处理方式实际是基于以下两点考虑。
因此,问题选项呈现采用了具体细分的列举,而细分项的合并化简,则将在问卷回收后,根据用户的实际反应来处理。
问卷投出去一段时间后,样本池渐渐上涨,内容偏好的数据饼图五彩斑斓地分布起来。这时就发现问卷选项细碎的不方便之处-同时考虑18个选项远远**出了人类工作记忆的负荷,让分析过程颇有些尾大不掉。当然这是意料之中的。如前所述,之所以把选项粒度做得很小,是希望通过用户的实际选择模式来找到相关联的内容。因此,首先要使用一下因子分析的方法,把数据进行浓缩。
岔开几句简单说说因子分析的用途。所谓因子分析,是处理多变量数据的一种常用的预处理方法,使用场景是当实际用于测量的变量较多且相关时,可以将比较琐碎繁多的变量,用几个易于解释的因子表达出来,从而更清晰地展示数据的结构和规律。拿这个项目来说,我们得到的多选题数据是用多重二分法表示的-每一个选项作为一个单独变量-题目反应数据共包括18个变量(如下图)。显然这些变量之间是存在相关关系的,存在归纳的可能,这正符合因子分析的使用场景。

因子分析使用SPSS完成,操作过程略去不表,分类结果如下图所示,将18个选项浓缩为5类因子。根据每个选项在各因子上的载荷(也就是原始选项和因子之间的相关系数),可以看出该因子大概代表了哪一类内容。为了便于理解,分别给它们起了一个比较直观的名字。如下图所示。
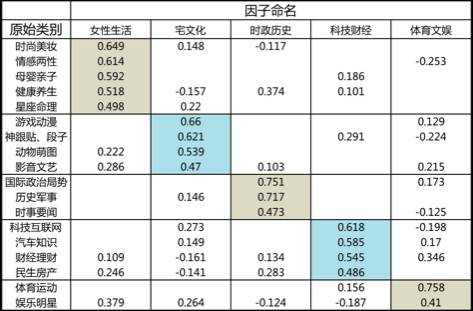

5个因子作为新的变量保存下来(如下图,注意保留下来的变量已经标准化为Z分数),留作后续进行用户聚类的依据。每个用户对某个因子分数越高,就意味着对该因子对应内容的偏好程度更强。例如第2个用户,就明显是“女性生活”因子相关内容的重度浏览者。
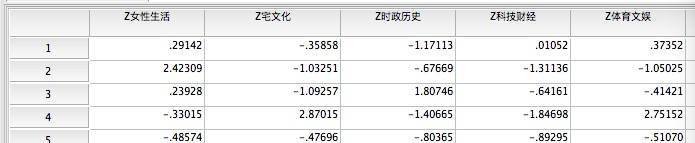
完成了数据化简,接下来根据用户在五个内容偏哈因子上的得分,对用户进行聚类分析。由于因子本身为Z分数,不用再进行标准化处理,直接分析即可。
这里再岔开几句简单说说聚类分析的原理。聚类算法的原理是通过计算各个案例点在变量空间中的距离远近(SPSS中计算距离的方法有30多种,大多数情况只选择默认设置的欧式距离就好),来把它们分簇处理的。变量空间名字听起来挺厉害,其实就是把n个变量当作n个坐标轴,参照三个维度构成三维“空间”的说法,将n个变量的情境称为n维空间。每个case在这n个变量上的取值,构成了一个n维坐标,根据坐标可以计算case间的距离,根据距离远近形成不同的分类簇。例如,上图表格中每一行都是一个五维坐标向量,描述了该行对应用户在“内容偏好空间”的位置,不同用户位置间的距离越近,就越可能被归为一类。
聚类分析仍使用SPSS完成,结果如下表所示。表格中数字代表每类用户对特定内容的偏好程度,数字越大偏好程度越高。根据几类用户的内容偏好模式分别起一个鲜明易记的名字,例如,给更偏好“女性生活”与“宅文化”内容的用户打上“时尚丽人”的标签。
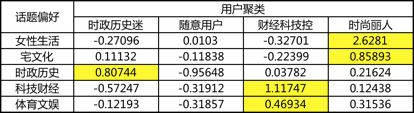
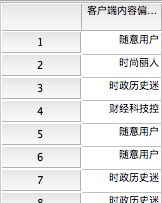
现在每一位样本中的用户都有了一个内容偏好标签,这个标签也保存为一个新的变量(如下图),留待与其它题目进行交叉分析。
首先就可以用内容标签与人口学变量来交叉分析一下,验证一下偏好某类内容的用户是否具有比较特殊的人口学属性。结果如下图所示(具体数据略)。可以看到,尽管由于样本中男性比例偏大造成一些bias,相对趋势的比较还是验证了很多印象:例如“时尚丽人”中年轻女性的比例显著偏高,“财经科技控”高学历高收入比例显著高等等。
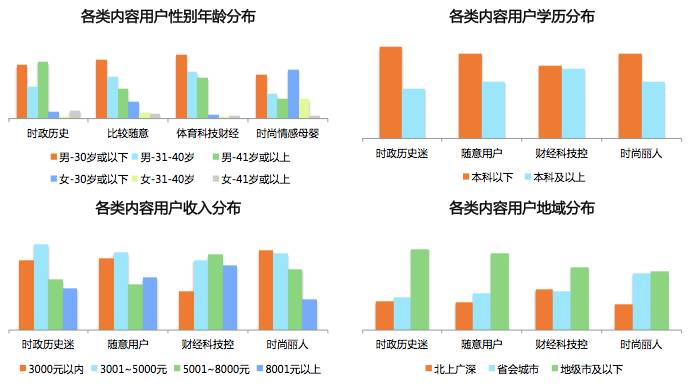
纳入与人口学变量的交叉分析结果,最终得到的用户分类如下表所示。从样本占比推断,“随意用户”和“时政历史迷”最有可能是客户端主流人群,这与业务经验得到的印象是一致的。
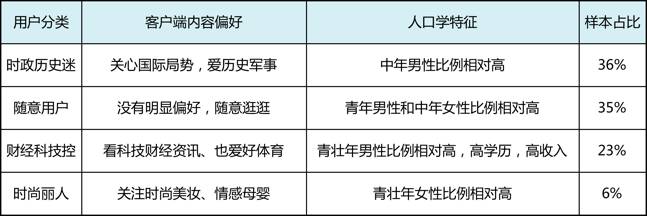
现在关键的问题来了,画像的几类人群,哪类是话题版块的核心用户、需要重点发力运营呢?
首先看看活跃用户中各类用户的占比(活跃度根据问卷中觉知情况和使用频次的问题答案来判断)。由下图可以看到,活跃用户的类别分布和整体差异并不大-“随意用户”和“时政历史迷”占了最大的部分。这也符合预期,毕竟话题版块的流量从客户端整体渗透过来,各类用户体量上不应该有太大的差异
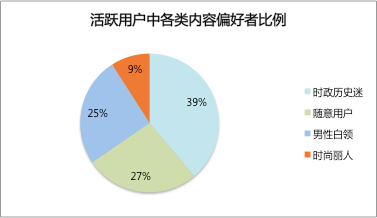
那么哪种用户的增量潜力比较大呢?这个问题反过来看比较清晰-我们可以这样假设,如果某类人群中活跃用户比例越大,满意度越高,那么这类用户更可能是话题版块的目标用户。
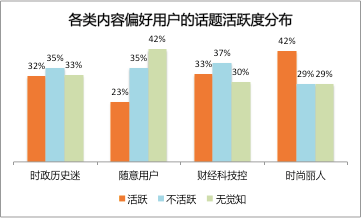
首先将活跃度与内容偏好进行交叉分析。可以看到,“时尚丽人”中话题使用活跃者占比最高(42%),无觉知者占比则最低(29%)-年轻女性用户看起来天然对话题讨论很敏感。
再看一下满意度的差异。年轻女性用户对话题社区各方面的满意度都高于其他用户,她们在话题社区玩得更开心。
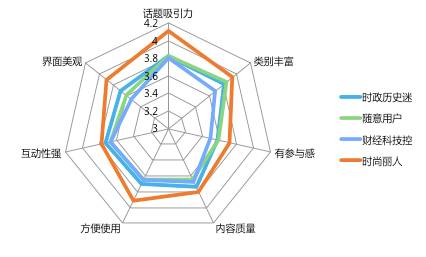
所以,给出结论&建议-年轻女性用户虽然在话题版块的体量不大,但她们的活跃度和满意度更高,讨论质量更好,对促进话题社区良性发展有很大帮助,可以从相关内容版块进行重点引流。而反过来,如果话题社区这种形式对“时尚丽人”独具吸引力,也可以将话题版块与时尚、母婴、情感等垂直频道打通,通过话题运营进行流量反哺。
最后,本例仅仅是基于调研目的灵活处理的一个例子,适合短平快的项目;如果需要系统了解用户,深入挖掘用户需求,更大的样本量和更扎实的定性研究依然是必不可少的。不过在日常工作中,有意识地以经济敏捷的方式扩展关于用户的基础知识,也不失为一种很好的积累沉淀吧。
(本案例数据和结论仅作为例子展示,不涉及真实情况)
作者:驴爷
来源:公众号:ME网易移动设计
版权:人人都是产品经理遵循行业规范,任何转载的稿件都**明确标注作者和来源,若标注有误,请联系主编**:419297645
