时间: 2021-07-30 10:56:18 人气: 16 评论: 0
很多人都说**数据分析的人比别人聪明,实际上他们“聪明”在拥有分析思维,今天我们就来说说常见的数据分析思维。

以下10种数据分析思维可能不**瞬间升级你的思维模式,但说不定**为你以后的工作带来“灵光一闪”的感觉,请耐心读完。
日常工作中,客户分群、产品归类、市场分级……许多事情都需要有分类的思维。关键在于,分类后的事物,需要在核心关键指标上能拉开距离!也就是说,分类后的结果必须是显著的。
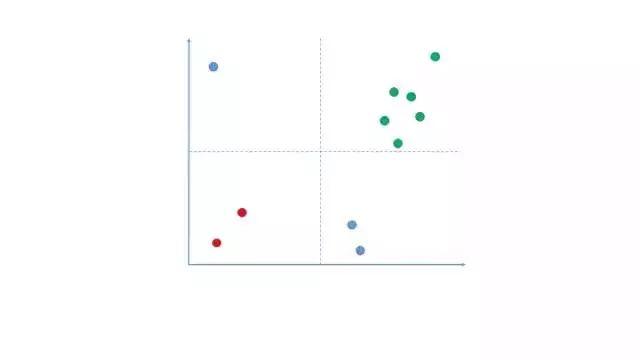
如图,横轴和纵轴往往是你运营当中关注的核心指标(当然不限于二维),而分类后的对象,你能看到他们的分布不是随机的,而是有显著的集群的倾向。
打个比方,经典的RFM模型依托收费的3个核心指标构建用户分群体系:最近一次消费时间(Recency)、消费频率(Frequency)、消费金额(Monetary)。

在R/M/F三个指标上,我们通过经验将实际的用户划分为以下8个区(如上图),我们需要做的就是促进不同的用户向更有价值的区域转移。也就是将每个付费用户根据消费行为数据,匹配到不同的用户价值群体中,然后根据不同付费用户群体的价值采用不同的策略。(如下表)

分类思维的发展之一是矩阵思维,矩阵思维不再局限于用量化指标来进行分类。许多时候,我们没有数据做为支持,只能通过经验做主观的推断时,是可以把某些重要因素组合成矩阵,大致定义出好坏的方向,然后进行分析。大家可以百度经典的管理分析方法“波士顿矩阵”模型。

这种思维方式已经比较普及了,漏斗分析分为长漏斗和短漏斗。长漏斗的特征是涉及环节较多,时间周期较长,常用的长漏斗有渠道归因模型,AARRR模型,用户生命周期模型等等;短漏斗是有明确的目的,时间短,如订单转化漏斗和注册漏斗。

但是,看上去越是普适越是容易理解的模型,它的应用越得谨慎和小心。在漏斗思维当中,我们尤其要注意漏斗的长度。
漏斗从哪里开始到哪里结束?漏斗的环节不该**过5个,漏斗中各环节的百分比数值,量级不要**过100倍(漏斗第一环节100%开始,到最后一个环节的转化率数值不要低于1%)。若**过了我说的这两个数值标准,建议分为多个漏斗进行观察。
理由是什么呢?**过5个环节,往往**出现多个重点环节,那么在一个漏斗模型中分析多个重要问题容易产生混乱。数值量级差距过大,数值间波动相互关系很难被察觉,容易遗漏信息。
我们观察指标,不仅要看单个指标的变化,还需要观察指标间的相互关系。有正相关关系(图中红色实线)和负相关关系(蓝色虚线),最好能时常计算指标间的相关系数,定期观察变化。

相关思维的应用太广了,往往是被大家忽略的。现在的很多企业管理层,面对的问题并不是没有数据,而是数据太多,却太少有有用的数据。相关思维的其中一个应用,就是能够帮助我们找到最重要的数据,排除掉过多杂乱数据的干扰。
如何执行呢?
你可以计算能收集到的多个指标间的相互关系,挑出与其他指标相关系数都相对较高的数据指标,分析它的产生逻辑,对应的问题,若都满足标准,这个指标就能定位为核心指标。
建议大家养成一个习惯,经常计算指标间的相关系数,仔细思考相关系数背后的逻辑,有的是显而易见的常识,比如订单数和购买人数,有的或许就能给你带来惊喜!另外,“没有相关关系”,这往往也**成为惊喜的来源。
一般说明逻辑树的分叉时,都**提到“分解”和“汇总”的概念。我这里把它变一变,使其更贴近数据分析,称为“下**”和“上卷”。

下**,就是在分析指标的变化时,按一定的维度不断的分解;而上卷是反方向的汇总。
下**和上卷并不是局限于一个维度的,往往是多维组合的节点,进行分叉。逻辑树引申到算法领域就是决策树。有个关键便是何时做出决策(判断)。当进行分叉时,我们往往**选择差别最大的一个维度进行拆分,若差别不够大,则这个枝桠就不在细分。能够产生显著差别的节点**被保留,并继续细分,直到分不出差别为止。经过这个过程,我们就能找出影响指标变化的因素。
很多问题,我们是找不到横向对比的方法和对象的,那么,和历史上的状况比就将变得非常重要。其实很多时候用时间维度的对比来分析问题,便于排除掉一些外在的干扰,尤其适合创新型的分析对象,比如一个新行业的公司,或者一款全新的产品。

时间序列的思维有三个关键点:
时间序列思维有一个子概念不得不提一下,就是“生命周期”的概念。产品生命周期**(PLC模型)是由美国经济学家Raymond Vernon提出的,即一种新产品从开始进入市场到被市场淘汰的整个过程。用户、产品、人、事都存在生命周期。

随着计算机运算能力的提高,队列分析(cohort analysis)这一方式逐渐展露头脚。从经验上看,队列分析就是按一定的规则,在时间颗粒度上将观察对象切**,组成一个观察样本,然后观察这个样本的某些指标随着时间的演进而产生的变化。目前使用得最多的场景就是留存分析。

队列分析中,指标其实就是时间序列,不同的是衡量样本。队列分析中的衡量样本是在时间颗粒上变化的,而时间序列的样本则相对固定。
循环/闭环的概念可以引申到很多场景中,比如业务流程的闭环、用户生命周期闭环、产品功能使用闭环、市场推广策略闭环等等。

业务流程的闭环是管理者比较容易定义出来的,列出公司所有业务环节,梳理出业务流程,然后定义各个环节之间相互影响的指标,跟踪这些指标的变化,能从全局上把握公司的运行状况,如脉脉的业务流程(如下图)。有了循环思维的好处是,你能比较快的建立有逻辑关系的指标体系。

逻辑思维即明白价值链、明白各项数据中的关系,也就是因果关系。
该方法的关键在于明白其中的关系要求你对这项工作要了解、熟悉,要细致和慎密,要清楚充分性和必要性的关系。实际上也就是指:你需要哪些数据?如何获得这些数据?数据之间的关系如何?这里最常见的手段就是A/B test啦。
那么如何细化一下这个概念?
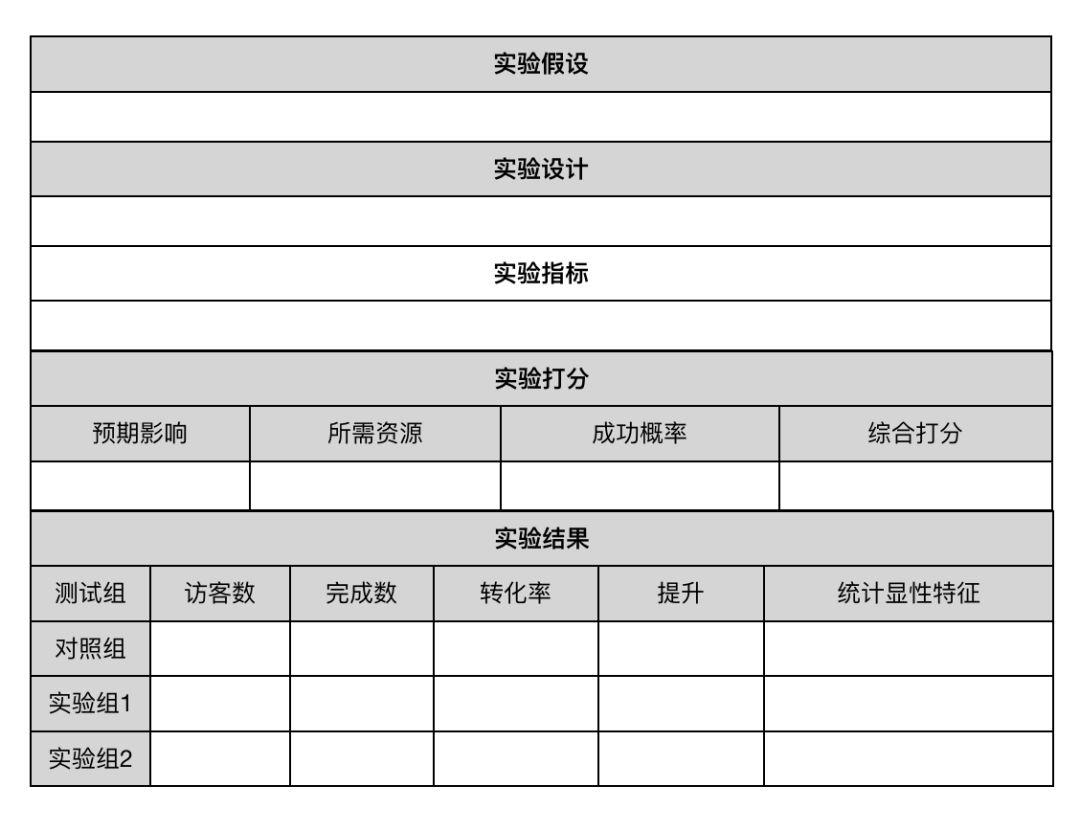
现在数据获取越来越方便,在保证数据质量的前提下,希望大家多做实验,多去发现规律,可以按如下表格来做实验。
指数化思维是今天分享的10个思维当中最重要的。许多管理者面临的问题是“数据太多,可用的太少”,这就需要“降维”了,即要把多个指标压缩为单个指标。指数化思维就是将衡量一个问题的多个因素分别量化后,组合成一个综合指数(降维),来持续追踪的方式。

指数化的好处非常明显:
指数的设计是门大学问,这里简单提三个关键点:
PS:独立穷尽原则,即你所定位的问题,在搜集衡量该问题的多个指标时,各个指标间尽量相互独立,同时能衡量该问题的指标尽量穷尽(收集全)。例如当运营人员考虑是否需要将自己的内容分发到其他平台时,他可以采用指数化思维来整体评分。

10种数据分析的思维方式我们分享完了,当然在我们的工作中不只这10种,我们将**在以后的内容中分享给大家,除此之外如果大家有额外的好的数据分析思维方式,可以分享给我噢!
本文由 @DataHunter 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
