时间: 2021-07-30 10:59:02 人气: 11 评论: 0

本文是 《如何七周成为数据分析师》的第三篇教程,如果想要了解写作初衷,可以先行阅读七周指南。温馨提示:如果您已经熟悉Excel,大可不必再看这篇文章,或只挑选部分。
在 《如何七周成为数据分析师01:常见的Excel函数全部涵盖在这里了》 和《如何七周成为数据分析师02:Excel技巧大揭秘》 后,今天这篇文章讲解实战,如何运用上两篇文章的知识进行分析。内容是新手向的基础教程。
为了更好的了解数据分析师这个岗位,我用爬虫爬取了招聘网站上约5000条的数据分析师职位数据。拿数据分析师进行数据分析。
数据真实来源于网络,属于网站方,请勿用于商业用途。
操作版本:Excel 2016 Mac版。文件大小约2M。
演示过程分为五个步骤:明确目的,观察数据,清洗数据,分析过程,得出结论。
这也是通常数据分析的简化流程。
数据分析的大忌是不知道分析方向和目的,拿着一堆数据不知所措。一切数据分析都是以业务为核心目的,而不是以数据为目的。
永远不要妄图在一堆数据中找出自己的结论,太难。目标在前,数据在后。哪怕给自己设立一个很简单的目标,例如计算业务的平均值,也比没有方向好。因为有了平均值可以想数字比预期是高了还是低了,原因在哪里,数据靠谱吗?为了找出原因还需要哪些数据。
既然有五千多条数据分析师的岗位数据。不妨在看数据前想一下自己**怎么运用数据。
等等。
有了目标和方向后,后续则是将目标拆解为实际过程。
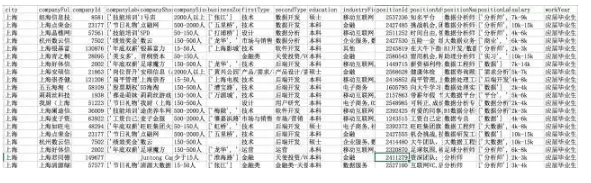
拿出数据别急切计算,先观察数据。
字段名称都是英文,我是通过Json获取的数据,所以整体数据都较为规整。绝大部分数据源的字段名都是英文。因为比起拼音和汉字,它更适合编程环境下。
先看一下columns的含义:
city:城市
companyFullName:公司全名
companyId:公司ID
companyLabelList:公司介绍标签
companyShortName:公司简称
companySize:公司大小
businessZones:公司所在商区
firstType:职位所属一级类目
secondType:职业所属二级类目
education:教育要求
industryField:公司所属领域
positionId:职位ID
positionAdvantage:职位福利
positionName:职位名称
positionLables:职位标签
salary:薪水
workYear:工作年限要求
数据基本涵盖了职位分析的所需。职位中的职位描述没有抓下来,一来纯文本不适合这次初级分析,二来文本需要分词以及文本挖掘,后续有机**再讲。
首先看一下哪些字段数据可以去除。companyId和positionId是数据的唯一标示,类似该职位的身份证号,这次分析用不到关联vlookup,我们先隐藏。companyFullName和companyShortName则重复了,只需要留一个公司名称,companyFullName依旧隐藏。
尽量不删除数据,而是隐藏,保证原始数据的完整,谁知道以后**不**用到呢?
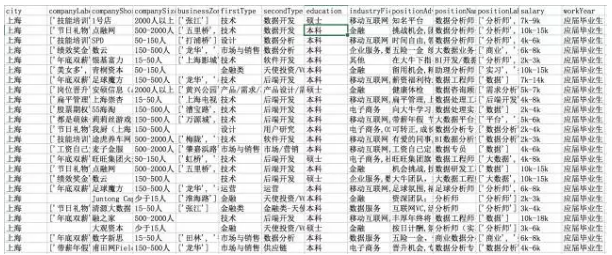
接下来进行数据清洗和转换。因为只是Excel级别的数据分析,不**有哑变量离散化标准化的操作。我简单归纳一下。
数据的缺失值很大程度上影响分析结果。引起缺失的原因很多,例如技术原因,爬虫没有完全抓去,例如本身的缺失,该岗位的HR没有填写。
如果某一字段缺失数据较多(**过50%),分析过程中要考虑是否删除该字段,因为缺失过多就没有业务意义了。
Excel中可以通过选取该列,在屏幕的右下角查看计数,以此判别有无缺失。
companyLabelList、businessZones、positionLables都有缺失,但不多。不影响实际分析。
一致化指的是数据是否有统一的标准或命名。例如上海市数据分析有限公司和上海数据分析有限公司,差别就在一个市字,主观上肯定**认为是同一家公司,但是对机器和程序依旧**把它们认成两家。**影响计数、数据透视的结果。
我们看一下表格中的positionName
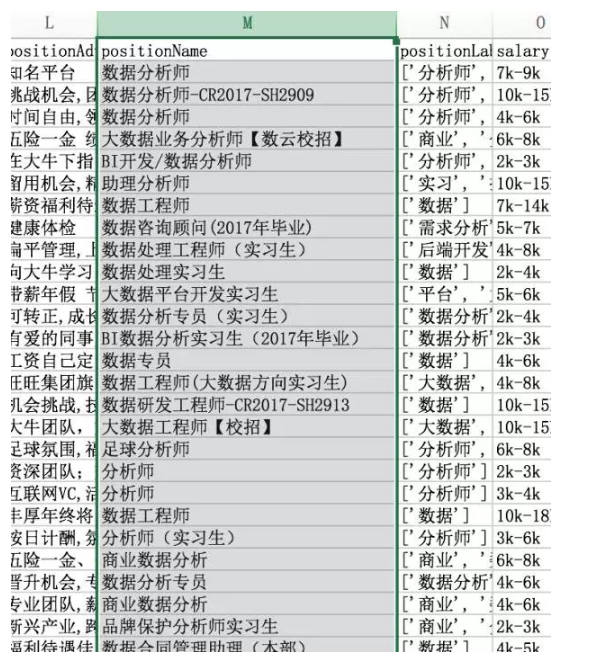
各类职位千奇百怪啊,什么品牌保护分析师实习生、足球分析师、商业数据分析、大数据业务分析师、数据合同管理助理。并不是纯粹的数据分析岗位。
为什么呢?这是招聘网站的原因,有些职位明确为数据分析师,有些职位要求具备数据分析能力,但是又干其他活。招聘网站为了照顾这种需求,采用关联法,只要和数据分析相关职位,都**在数据分析师的搜索结果中出现。我的爬虫没有过滤其他数据,这就需要手动清洗。
这**不**影响我们的分析?当然**。像大数据工程师是数据的另外发展方向,但不能归纳到数据分析岗位下,后续我们需要将数据分析强相关的职位挑选出来。
脏数据是分析过程中很讨厌的环节。例如乱码,错位,重复值,未匹配数据,加密数据等。能影响到分析的都算脏数据,没有一致化也可以算。
我们看表格中有没有重复数据。
这里有一个快速窍门,使用Excel的删除重复项功能,快速定位是否有重复数据,还记得positionId么?因为它是唯一标示,如果重复了,就说明有重复的职位数据。看来不删除它是正确的。
对positionId列进行重复项删除操作
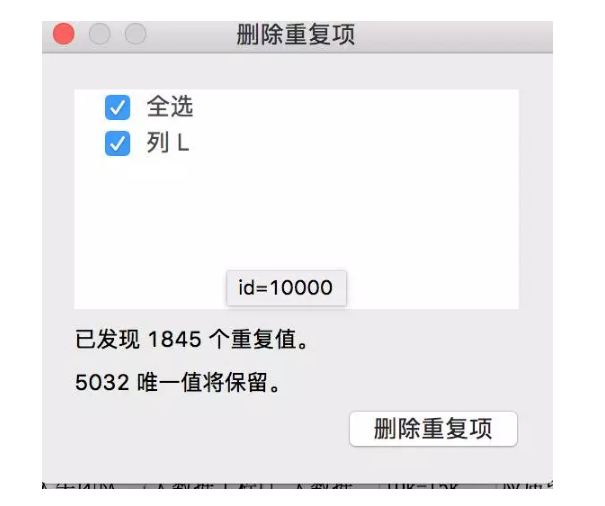
有1845个重复值。数据重复了。这是我当时爬取完数据时,将北京地区多爬取一次人为制作出的脏数据。接下来全选所有数据,进行删除重复项,保留5032行(含表头字段)数据。
数据标准结构,就是将特殊结构的数据进行转换和规整。
表格中,companyLableList就是以数组形式保存(JSON中的数组)
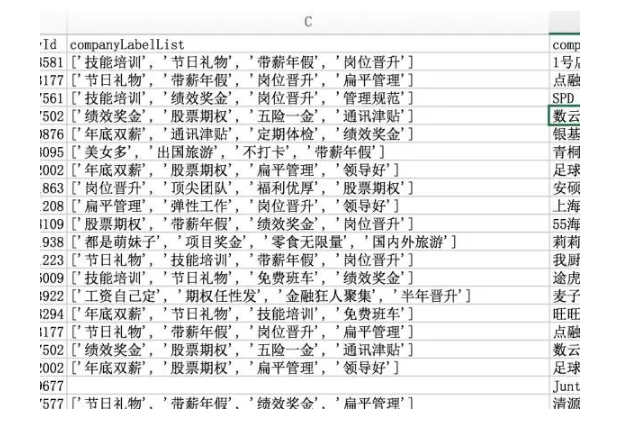
看来福利倒是不错,哈哈,不过这**影响我们的分析。businessZones、positionAdvantage和positionLables也是同样问题,我们后续得将这类格式拆分开来。

薪水的话用了几K表示,但这是文本,并不能直接用于计算。而且是一个范围,后续得按照最高薪水和最低薪水拆成两列。
OK,数据大概都了解了,那么下一步就是将数据洗干净。
数据清洗可以新建Sheet,方便和原始数据区分开来。
先清洗薪水吧,大家肯定对钱感兴趣。将salary拆成最高薪水和最低薪水有三种办法。
一是直接分列,以”-“为拆分符,得到两列数据,然后利用替换功能删除 k这个字符串。得到结果。
二是自动填充功能,填写已填写的内容自动计算填充所有列。但我这个版本没有,就不演示了。
三是利用文本查找的思想,重点讲一下这个。先用 =FIND(“k”,O2,1)。查找第一个K(最低薪酬)出现的位置。
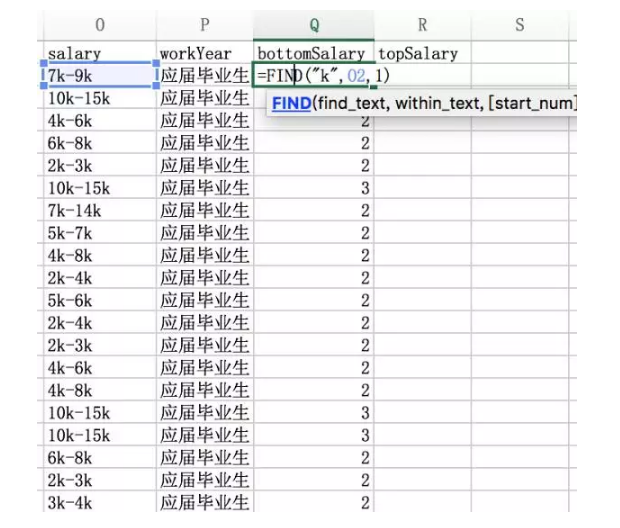
我们知道第一个k出现的位置,此时=LEFT(O2,FIND(“k”,O2,1))得到的结果就是 7K,要去除掉k,FIND(“k”,O2,1)再减去1即可。
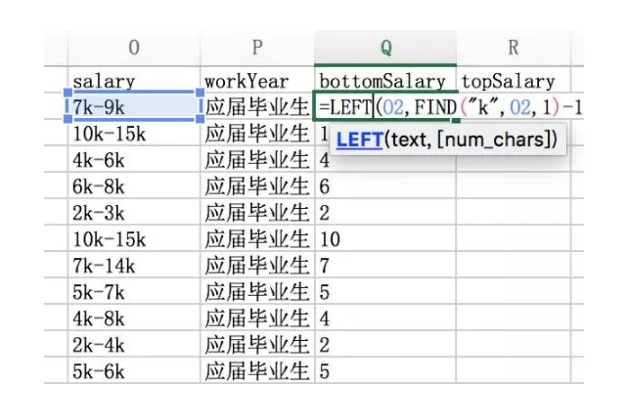
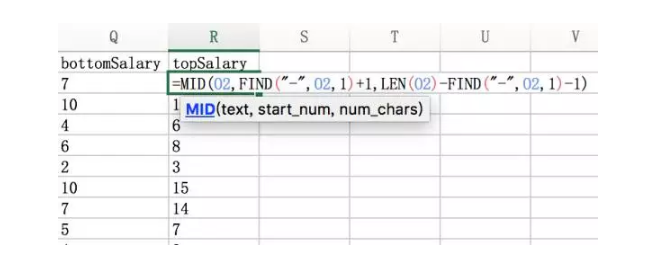
最高薪水也是同样的思路,但不能使用k,因为第二个薪水位置不固定。需要利用find查找”-“位置,然后截取 从”-” 到最后第二个位置的字符串。
=MID(O2,FIND(“-“,O2,1)+1,LEN(O2)-FIND(“-“,O2,1)-1)
因为薪水是一个范围,我们不可能拿范围计算平均工资。那怎么办呢?我们只能取最高薪水和最低薪水的平均数作为该岗位薪资。这是数据来源的缺陷,因为我们并不能知道应聘者实际能拿多少。这是薪水计算的误差。
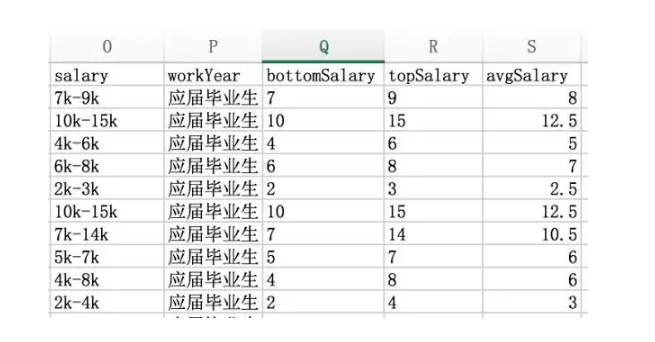
我们检查一下有没有错误,利用筛选功能快速定位。

居然有#VALUE!错误,看一下原因。
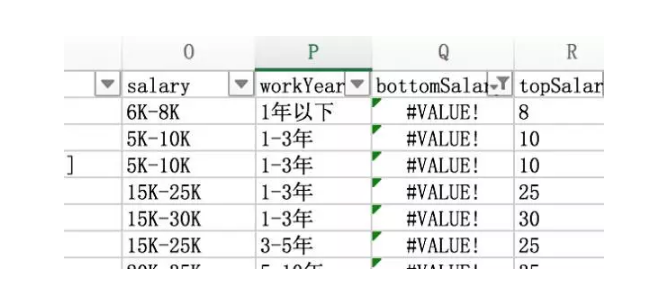
原来是大写K,因为find对大小写敏感,此时用search函数,或者将K替换成k都能解决。
另外还有一个错误是很多HR将工资写成5K以上,这样就无法计算topSalar。为了计算方便,将topSalary等于bottomSalary,虽然也有误差。
这就是我强调数据一致性的原因。
companyLabelList是公司标签,诸如技能培训啊、五险一金啊等等。直接用分列即可。大家需要注意,分列**覆盖掉右列单元格,所以记得复制到最后一列再分。
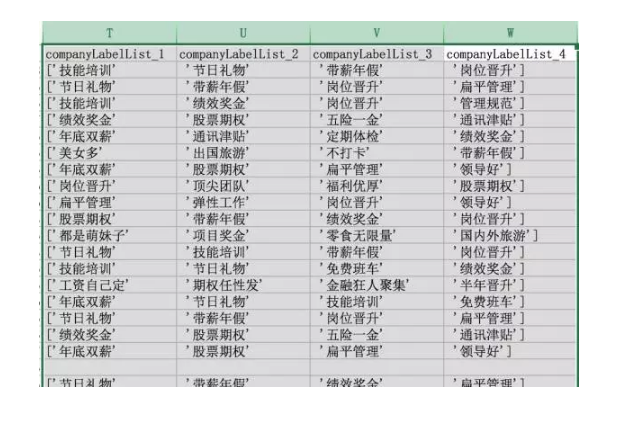
符号用搜索替换法删除即可。
positionLables、positionAdvantage、businessZones同样也可以用分列法。如果观察过数据**知道,companyLabelList公司标签都是固定的内容,而其他三个不是。这些都是HR自己填写,所以就**有各种乱七八糟不统一的描述。

这些内容均是自定义,没有特别大的分析价值。如果要分析,必须花费很长的时间在清洗过程。主要思路是把这些内容统一成几十个固定标签。在这里我将不浪费时间讲解了,主要利用Python分词和词典进行快速清洗。
因为时间和性价比问题,positionAdvantage和businessZones我就不分列了。只清洗positionLables职位标签。某一个职位最多的标签有13个。
[‘实习生’, ‘主管’, ‘经理’, ‘顾问’, ‘销售’, ‘客户代表’, ‘分析师’, ‘职业培训’, ‘教育’, ‘培训’, ‘金融’, ‘证**’, ‘讲师’]
这个职位叫金融证**分析师助理讲师助理,我真不知道为什么实习生、主管、经理这三个标签放在一起,我也是哔了狗了。反正大家数据分析做久了,**遇到很多Magic Data。
接下来是positionName,上文已经讲过有各种乱七八糟或非数据分析师职位,所以我们需要排除掉明显不是数据分析师的岗位。
单独针对positionName用数据透视表。统计各名称出现的次数。
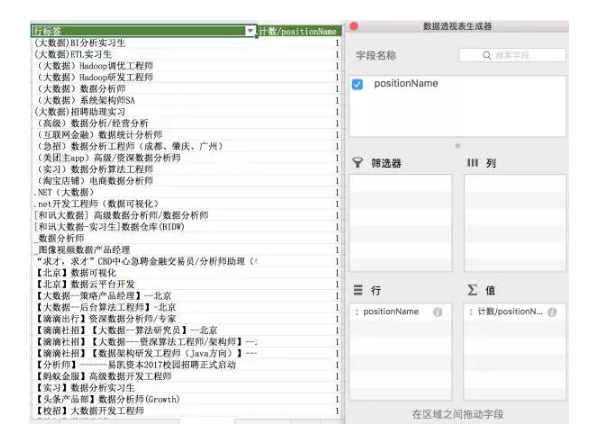
出现次数为3次以下的职位,有约一千,都是各类特别称谓,HR你们为什么要这样写…要这样写…这样写。更改职位名称似乎不现实,那就用关键词查找的思路,找出包含有数据分析、分析师、数据运营等关键词的岗位。虽然依旧**有金融分析师这类非纯数据的岗位。
用find和数组函数结合,shift+ctrl+enter输入。就得到了多条件查找后的结果。
=IF(COUNT(FIND({“数据分析”,”数据运营”,”分析师”},M33)),”1″,”0″)
单纯的find 只**查找数据分析这个词,必须嵌套count才**变成真数组。
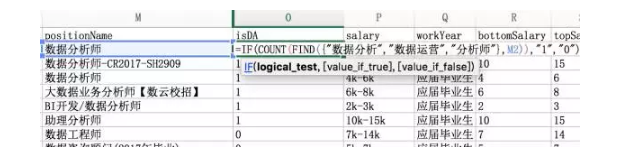
1为包含,0不包含。将1过滤出来,这就是需要分析的最终数据。
当然大家如果感兴趣,也可以看一下大数据工程师,数据产品经理这些岗位。
分析过程有很多玩法。因为主要数据均是文本格式,所以偏向汇总统计的计算。如果数值型的数据比较多,就**涉及到统计、比例等概念。如果有时间类数据,那么还**有趋势、变化的概念。
整体分析使用数据透视表完成,先利用数据透视表获得汇总型统计。
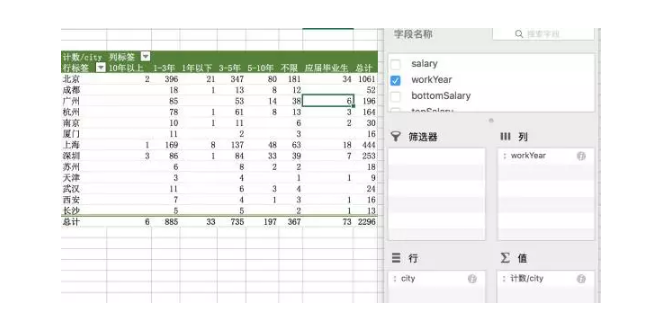
看来北京的数据分析岗位机**远较其他城市多。1-3年和3-5年两个时间段的缺口更大。应届毕业生似乎比1年一下经验的更吃香。爬取时间为11月,这时候校招陆续开始,大公司**
有线下校招,实际岗位应该更多。小公司则倾向发布。这是招聘网站的限制。
看一下公司对数据分析师的缺口如何。
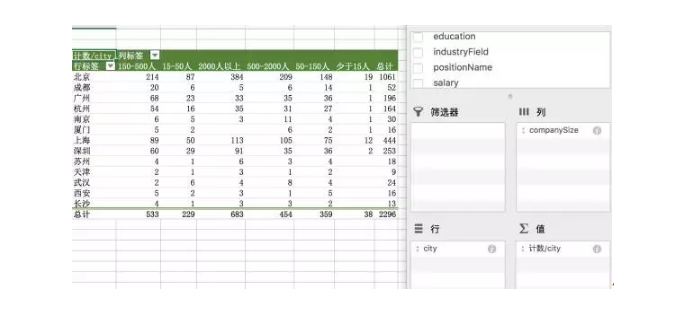
似乎是公司越大,需要的数据分析师越多。
但这样的分析并不准确。因为这只是一个汇总数据,而不是比例数据,我们需要计算的是不同类型企业人均招聘数。
如果北京的互联网公司特别多,那么即使有1000多个岗位发布也不算缺口大,如果南京的互联网公司少,即使只招聘30个,也是充满需求的。
还有一种情况是企业刚好招聘满数据分析师,就不发布岗位了,数据包含的只是正在招聘数据分析师的企业,这些都是限制分析的因素。我们要明确。
有兴趣大家可以深入研究。
看一下各城市招聘Top5公司。
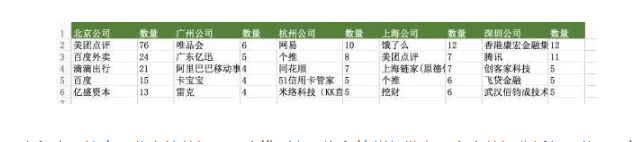
北京的美团以78个数据分析职位招聘力压群雄,甚至一定程度上拉高了北京的数据。而个推则在上海和杭州都发布了多个数据分析师职位,不知道是HR的意外,还是要大规模补充业务线(在我写这篇文章的时候,约有一半职位已经下线)。
比较奇怪的是阿里巴巴并没有在杭州上榜,看来是该阶段招聘需求不大,或者数据分析师有其他招聘渠道。
没有上榜不代表不要数据分析师,但是上榜的肯定现阶段对数据分析师有需求。
我们看一下数据分析师的薪水,可能是大家最感兴趣的了。
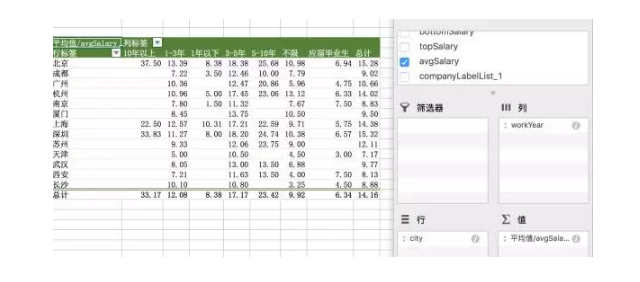
我们看到南京、西安在应届生中数据最高,是因为招聘职位不多,因为单独一两个企业的高薪影响了平均数,其余互联网二线城市同理。当工作年限达到3年以上,北上深杭的数据分析师薪资则明显高于其他城市。
数据**有误差性么?**的,因为存在薪资极值影响。而数据透视表没有中位数选项。我们也可以单独用分位数进行计算,降低误差。
薪资可以用更细的维度计算,比如学历、比如公司行业领域,是否博士生远高于本科生,是否金融业薪资高于O2O。
另外数据分析师的薪资,可能包括奖金、年终奖、季度奖等隐形福利。部分企业**在positionAdvantage的内容上说明,大家可以用筛选过滤出16薪这类关键词。作为横向对比。

我们看一下数据分析的职位标签,数据透视后汇总。
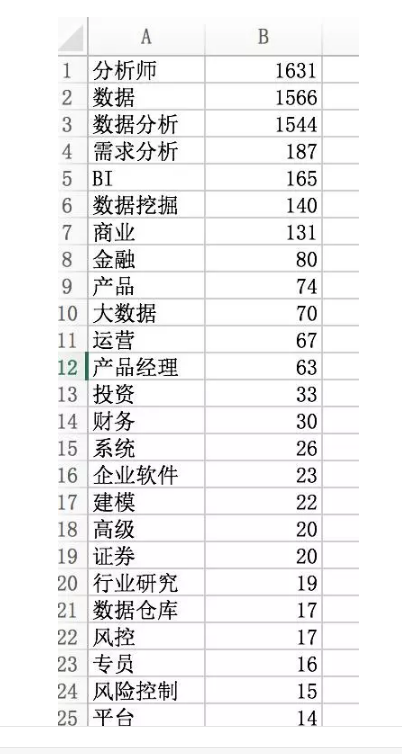
分析师、数据、数据分析是最多的标签。除此以外,需求分析,BI,数据挖掘也出现在前列。看来不少数据分析师的要求掌握数据挖掘,将标签和薪水关联,是另外一种分析思路。职位标签并不是最优的解法,了解一个职位最好的必然是职位描述。
分析过程不多做篇幅了,这次实战比较简单,后续文章**再讲解, 主要使用数据透视表进行多维度分析,没有其他复杂的技巧。下图很直观的展现了多维度的应用。
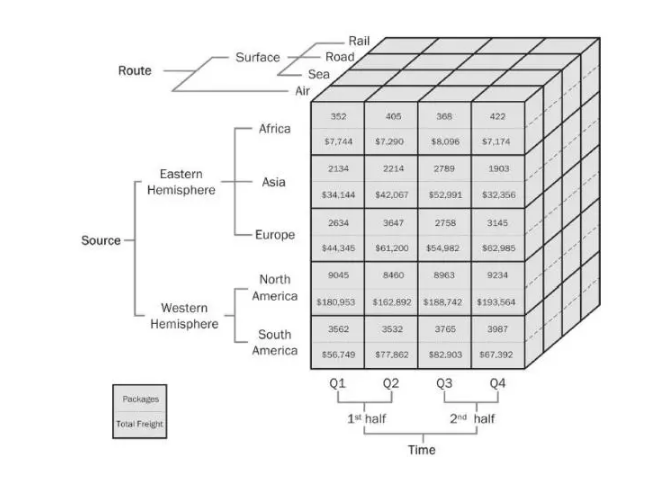
我们的分析也属于多维度,城市、工作年限、企业大小、企业领域等,利用不同维度形成一个直观的二位表格,而维度则是通过早期的数据清洗统一化标准化。这是一种很常见的分析技巧。
后续的数据报告,涉及到可视化制作,因为字不如表、表不如图,就放在第二周讲解。
最后多强调几下:
如果这个数据大家看到其他好玩的,可以一并留言告诉我。
Excel的内容差不多就结束了,之后**开始第二周数据可视化的讲解。
如何七周成为数据分析师01:常见的Excel函数全部涵盖在这里了
秦路,微信公众号ID:tracykanc,人人都是产品经理专栏作家。
本文由 @秦路 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自PEXELS,基于CCO协议
