时间: 2021-07-30 11:11:14 人气: 5 评论: 0
本文分享点是通过用户热词反推用户特征,希望对用户研究、商业分析、数据分析的同事有帮助。
在进**前,听说互联网产品都喜欢做用户画像调研,但成功应用没几个。进公司后看了几份用户画像报告,基本点面都覆盖了,数据和分析也没什么偏差,但不知道解决哪些问题。所以这里我先探讨两个问题,什么是用户画像,为何要做用户画像。
刚入调研的行业时候,觉得调研是无所不能,后来觉得调研无所能。其实关键是我们想清楚两个问题:一是我们解决什么问题,二是用户能回答哪些问题。
自从进了**,才大概了解到一个产品工作流程:
商业分析->产品交互DEMO->供应商BD->产品设计->前后台开发->市场推广->用户运营->售后客服->商业分析(重头开始,迭代2)
可以看到,我们常面对三类问题:产品设计、市场和技术。针对这三类问题,用户能回答哪些?答案是显然的:
回到刚才第一个问题,什么是用户画像?这个是什么不重要,重要的是我们要解决什么问题。一般而言,用户画像是解决市场推广问题,较少解决产品设计问题的调研报告。
作为一个用研同事,我们经常面对两个问题:一是调研报告出来后就凉在那里,似乎没起什么作用;二是产品同事经常报怨,不知道用户有哪些需求,如何解决目前困难。
如前面谈及,用户研究不是无所不能,它仅是提高产品/市场工作效率的工具之一,但不能代替各同事专业技能。或许有人说,这是你们用研没有做好做得深入,没有突破。
实际上,让用研同事入门产品设计或品牌推广专业技能,大概需要半年时间,然后才能提出一些专业解决方案。但没人等得起半年,最多等2周,所以调研报告解决不了产品经理的问题。
后来,作为用研,我调入到产品组,再后来调入品牌组,每个组呆了半年,自己切入产品设计和品牌推广具体工作,才知道大概需要是哪些东西,如何解决。
但假如大家没有这个条件,可让产品经理先说说潜在几个解决方案,然后每个方案需要获取哪些数据来验证是否可行。这样用研项目才**有价值。用户研究再深,也不能代替设计师的活,画出蒙罗丽莎。
在品牌组常被问到一个问题:用户具有哪些特征,他们喜欢什么东西?当这个问题经常被提问,就有觉得有解决的必要,其实不是,是我们看到这个答案如何应用:
从上述可以看到,我们回答“用户喜欢什么东西”是有应用价值,因此我们清楚我们需要收集哪些数据,调研哪些问题。
传统用户画像调研,基本都是通过用户访谈+问卷调查完成。在报告综述的时候,基本都是采取调查数据来总结归纳。但后来我们多少发现,无论我们问了多少个问题,用户画像还是不清晰的。
例如,****用户喜欢看电影,比非****用户高出10%,但我们不能以是否喜欢看电影作为****用户核心特征。因为在看电影这件事情上,也有很多非****也喜欢。
如此情况经常发生,是否喜欢逛街、购物、旅游、看书、听音乐、玩游戏等等,您**发现我们很难用几百个问卷调查指标来将****用户生活形态描绘出来,因为95%指标都缺乏显性差异。这就是现实世界:mess。假如用户问卷调查数据描绘一群人的生活形态,就像下图的感觉,模糊大概知道是两个人,但有点看不清。

若回想为何看不清用户形态,总结原因有两个:
①笔触太粗:即我们提问指标不够多,问卷调查一般可覆盖用户生活形态的100个指标,但在这100个指标中找出有效指标,估计不到10个。
②颜色太少:很多时候我们仅能问用户是否喜欢某件事情(2选项),或根据“非常喜欢”、“喜欢”、”一般“、”不喜欢“、”非常不喜欢“(5选项),甚至评分制(10选项),用户根据自己感知打分,敏感度还是有限的。一般情况下,像评分制,用户根据自己感觉打分,一般仅能区分5-6级别差异。但现实世界是,在一件事情态度上,可以有几千种态度差异,后面**讲述。
后来我们尝试将用户后台数据全部提取,大约有300-500个指标。但受信息安全限制,我们仅能拿到自己和合作部门数据,而电商数据、豆瓣阅读喜欢的数据,基本都是缺乏的。
不过有了后台数据,用户画像是稍微清晰点。这里清晰并不单是数据指标多,而是纬度更多。因为这300个指标中,经过因子分析,我们发现用户尽在10个纬度上是有差异。意思是说,这300个指标可整合为10个指标,来描述用户差异,其余大部分指标都是基于这10个指标演变而成。下面可以概括有哪些指标:
经过更多纬度,我们可将用户画像描写得更细,如下图。现在大家还是猜得他们是谁?相信很多人**猜到是一个成年男人和小孩,但不太确定他们特质。这就是将外部调研数据和内部后台数据结合输出的用户画像报告。
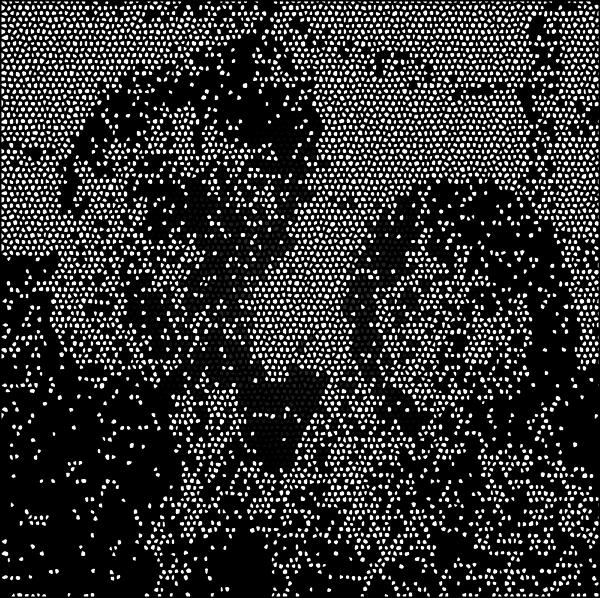
经过后台数据补充,我们可以发现更多有区隔性的特征指标,但用户内心诉求还是不太清楚。在这个时候,我们跟微趋势团队探讨如何利用文本挖掘技术,来还原用户画像。
抽象地理解,我们想让每个点不仅是黑白两个颜色,而是有6万4千多个的真彩色。转换成操作方法,就是在一个事情态度上,我们不希望仅检测用户用户是否喜欢,而是检测到他喜欢哪些东西。但这里有几个挑战点:
于是,我整理了两个样本,分别是100w**用户和100w非**用户,提取最近一个月在**微博所发布文本内容,用微趋势系统做文本挖掘,看看用户常提及那些词。
操作流程是顺利的,但微博文本中存在大量广告杂质,几乎占据整体数据量50%。即使经过数据筛选清洗,用户高频次的词往往集中在两块:
生活用词:如知道,没有,可以,喜欢,开心,幸福,流泪,需要,觉得,希望等。这些词是日常用,故提及率很高,但缺乏具体的含义。
最近流行词(又称新词):如特么,光棍节,牛逼,期中考试,****,年费,呃呃呃呃呃,微博,坑爹,洗个澡。这些新词是基于对比原有词库,机器发现最近出现很多,但受节假日、活动运营、广告等因素严重影响,并非用户原始想法,故有效性也很低。
看来,在无限定主题情况下,用机器挖掘高频次热词来归纳用户特征是困难,微趋势文本挖掘技术更适合在特定关键词下一级关联分析,如****用户经常提及斗战神,微趋势可以分析用户在提及斗战神时候,关联提及哪些热词,那么我们就知道他们对斗战神的想法是什么。这非常适合做专题分析和传播。
假如在没主题或关键字限制情况下,机器挖热词是困难的,那么我们能否反过来,拿我们想测试热词列表,反过来计算每个词被提及的频次?于是,我们根据百度风云榜(http://top.baidu.com/)整理一份热词表,共有2300个当下热词,来分析用户提及哪些词语/事物更多,以此作为用户画像标签。
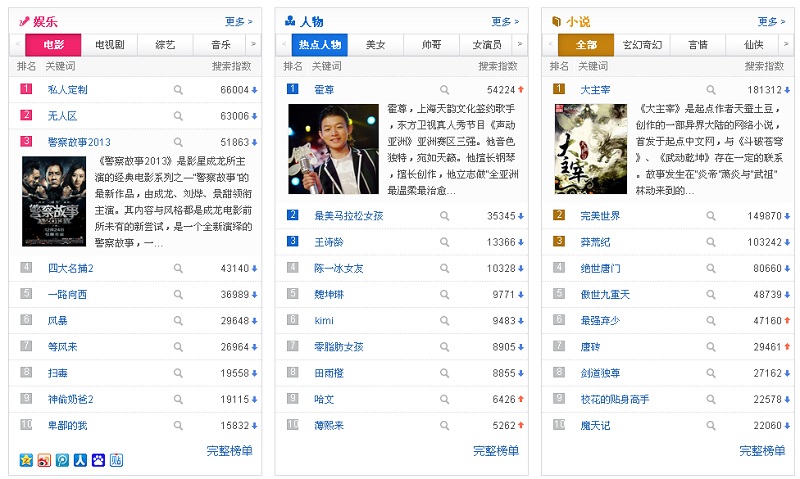
我们计算**用户不同年龄的提及热词的差异,找出不同年龄**用户关注哪些类目(如科幻**、喜剧**、剧情**),还算出不同年龄用户分别喜欢看哪些不同的科幻**(如13-15岁喜欢看雷神2,23-29岁喜欢看速度与激情)。通过这次用户喜好数据,我们就得出****用户画像及心理诉求。
到此,我们可以看到在某一个纬度上面,用户有千万种态度。用户画像也更加colorful和清晰。好吧,看得出是林志颖和kimi:)

回顾我们日常语言内容,**受到两个因素影响:
①社**流行:如最近流行电影、电视剧、段子、口头禅、网络新词等等。这些语言不管什么人都喜欢使用,成了社**流行。所以,我们日常生活中**提及很多社**流行事物。这些词语的特点是提及率高,用户间无差异。
②个人因素:70后和90后的说话词语是不一样,这是受年龄因素影响;屌丝和白富美说话内容是不一样,这是受经济因素影响。所以,我们可根据某群体的高频提及关键字,来作为这群用户的标签。
所以,若要找出不同年龄的****用户差异,通过“该年龄**用户提及该词频次/**用户提及该词频次”公式即可实现。
在统计关键字提及频次方面,有以下注意事项:
①关键词太长:用户**较少提及,如饥饿游戏2星火燎原,很多人**在微博上输入全称,故我们将关键字缩短,改为饥饿游戏2。
②关键词过于常见:如最近一部电视剧叫《晴天》。用户在微博上**因日常生活常提及这个词,故我们得剔除,不纳入分析。
③品牌词:微博上广告内容占总体信息量50%,拿品牌词统计关键字提及频次难以客观。
最后,利用热词表的提及频次来描述用户画像,他的优点和缺点在于同一地方。优点是,我们可以拿不同项目类型热词表,来查看用户在某个类目上的态度,如航空公司名称、牙膏牌子。只要热词越独特,其统计经准确性越高。只要有一批用户微博文本内容,我们就可以扩展很多类目描绘。但它的缺点是一致的,就是我们得整理出一份全面的热词表,且每个热词都有自己的独特性和当下流行性,不能像企鹅、老虎那样通用。
刚才提及,用户淘宝的购物数据、豆瓣电影/阅读数据、阿玛逊和当当的书单、百度关键词,用这些数据来描绘用户画像**更加清晰。原因是他们的数据更加精准,是用户喜好、搜索、购买行为数据,故百度、阿玛逊和豆瓣推荐一般都很精准。
其实,在大数据这个词发明之前,统计学、数据挖掘学都发展很多年。以前我们**用大量数据来做关联分析(如买啤酒的人倾向买纸尿布),或做聚类分析(如开通****有4个细分市场)。所以大数据并不是什么新鲜的事情。只是回到我们第一个问题,我们需要解决问题,只是用户画像,而不是预估用户下一次购买的商品。所以我们的数据精度就没有那么吹毛求疵。
当然,我们自身也没这块数据,也是不足。其实,说这段话的意思是,做调研,做什么事情,可以多尝试,但有时候得回过头来看,我们的问题或目标是什么,而方法招式都是辅助的。
最后,POST一下照**原图,看看他们的帅照,哈哈。

注:文中图**均来自网络
作者:邬嘉文,微信高级运营
本文由 @邬嘉文 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自unsplash,基于CC0协议
