时间: 2021-08-03 09:04:17 人气: 15 评论: 0
本文提及的项目是基于**多媒体实验室与北大深圳研究生院李革教授团队的高校联合项目,并通过文章简要回顾了目前学术界和工业界视频质量评估方向的发展状况。

**有多个视频业务线,点播视频有**视频、企鹅影视,短视频有微视、K歌,直播类有Now直播、企鹅电竞,实时传输类有**和微信的音视频通话、无线投屏和****议等。
用户对不同的产品有不同程度的期待:比如理想网络环境下,能不能在27寸显示器上看到毛发清晰可见的高清视频?使用3G等弱网环境时,视频通话能不能保证画面不频繁卡死?
对业务提供方来说,所有问题都可以归结为一个目的:在不同的网络状况下,保证用户最佳的视频观看体验。在整个视频链路中,我们可以精确度量大部分模块,如采集、上传、预处理、转码和分发。我们最未知的部分却恰恰是最关键的部分,即用户的视频观看体验到底怎么样。
本文旨在介绍业界视频质量评估进展并提出一种基于三维卷积神经网络的全参考视频质量评估算法。
视频质量评估的目的是准确地衡量视频内容的人眼感知质量。不经压缩的源视频因为码率太大而不适合互联网传输。我们必须使用标准的编解码器,如H.264/**C、HEVC,或自研编解码器来编码进而降低码流大小。然而,视频压缩**不可避免的引入压缩失真。
以H.264/**C压缩为例,图1给出了一个压缩失真示例图:
其中,白线左边对应未经压缩的原始画面,地面**块上的纹理清晰可见,背景的蓝天颜色过渡自然。白线右边对应压缩过的低码率视频画面。可以明显的看到压缩失真,**块纹理变得模糊不清,蓝天也因为块效应的原因出现了不自然的云条。

图1 H.264压缩失真截图。白线左边为高清源视频,白线右边为低码率压缩视频
在工业界和学术界,评估视频质量有两种常用方法:一是视频质量主观实验,二是视频质量客观算法。两种方法有各自的适用场景和局限性。
通过主观实验我们能精确衡量视频质量。在某些核心问题上,如codec性能比较,我们仍需要通过主观实验来得到确切的答案。同时,主观实验打分数据通常**用作验证客观质量评估算法性能的Ground Truth。完整的主观实验流程一般包含:
很显然,主观实验是一个周期长,费时费力的过程。诉诸主观打分来验证所有视频质量需求是不可行的。好在我们可以使用客观质量评估算法来模拟主观打分,进而实现视频质量评估。
然而,开发准确而快速的客观质量评估算法仍然是一项有挑战性的工作。
客观视频质量评估算法只需要计算视频的质量分数。
从工业界的角度来看,经典的客观算法有PSNR,SSIM [4],MS-SSIM [5],这些算法基于经典的信号保真度来判断失真视频与无损视频源的差异,再根据差异大小拟合出视频感知质量。近期的算法有VQM [6],从多个维度提取时空联合特征去逼近主观质量。
目前的主流算法有VMAF [7],使用机器学习方法对多个图像质量客观算法进行融合。借助于融合的思想,VMAF能够灵活的加入新的客观算法。另一方面,通过使用新的数据集来重新训练,VMAF也可以方便的迁移到细分维度的视频质量评估任务。
图像质量评估主要是衡量画面内失真在画面掩盖效应影响下的可感知程度。而视频质量评估不仅仅取决于画面内的失真,也包含时域内的失真和时域掩盖效应。这里掩盖效应可简单理解为背景的复杂程度。如果背景较复杂,我们称之为较强的掩盖效应,反之亦然。
举个例子,图一中滑板处于快速运动的状态,掩盖效应较强,所以滑板区域的失真更难察觉。而背景中蓝天部门是大**的光滑区域,掩盖效应较弱,细微的压缩失真也能容易察觉到。因此,在开发一个客观视频质量评估算法中,我们必须把视频固有的运动信息考虑进来。
在学术界,有很多相应的策略被提出。最常用对做法是提取两种特征,一种特征去描述画面质量,另一种特征去描述视频运动的大小。
比较主流的运动特征包含:TI (Temporal Information), 运动向量 (Motion Vector), 光流 (Optical Flow) 等。
这种做法最大的缺陷是完全剥离了画面信息和运动信息,视频不再被当作三维数据来处理,而是二维数据加一维数据来处理。
为了解决上述问题,另外一种比较直观的方法是对视频进行三维切** [8]。
如图2所示,我们使用(x, y, t)来标记空域和时域轴。这里切**如果与时间轴垂直,即(x, y)方向,那么切出来的就是传统意义上的视频帧;如果与时间轴平行,即(x, t) 或 (y, t)方向,我们就得到了时空联合的二维切**。在某种程度上,后两个切**包含了运动信息。对以上三种切**使用图像质量评估算法,再把切**分数融合起来,就能取得不错的质量提升。
尽管如此,三维切**还是没有最大程度的使用运动信息。
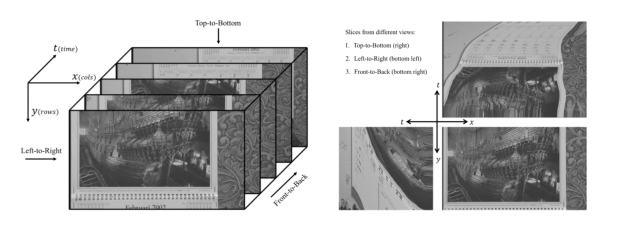
图2. 三维空间内视频切**示意图
有不少图**质量评估算法是基于经典的DCT或小波变换,再从变换系数中提取特征向量。
对视频而言,一种比较直观的拓展就是使用三维变换,如三维DCT变换,三维小波变换等。经过三维变换后,我们从变换系数中进一步提取特征来而做质量评估。这种方法保留了视频的时空联合信息,但是三维变换**引入复杂度过高的问题。
近年来深度学习在多个计算机视觉图**任务中取得了瞩目的成就。同时也有学者把二维神经网络扩展到三维神经网络来更好的处理视频任务 [9]。我们尝试使用三维卷积神经网络来学习时空特征并把它用到视频质量任务中。我们先给出基本的二维和三维卷积模块,再进一步介绍所提出的网络结构。
图3a给出了二维卷积核在二维输入上的卷积操作。为了避免歧义,我们假设是对二维图像进行卷积操作。其中输入图像大小为HxW,卷积核大小为kxk,图像时域深度和卷积核时域深度均为1。经过卷积运算输出仍为二维。输入输出均不包含任何运动信息。
图3b给出了二维卷积核在三维输入上的卷积操作。我们可以假设输入为一个画面大小为HxW,包含L帧的视频。这里卷积核的深度不再是1,而是跟视频帧数相同。经过卷积操作,输出仍为二维,且与图3a的输出大小相同。这种卷积操作有利用到视频前后帧的运动信息,但是只用一步卷积就把所有运动信息给吃掉了。
图3c给出了三维卷积核在三维输入上的卷积操作。与图3b相比,这里卷积核的深度为d,且d小于L。经过三维卷积操作,输出仍为三维。当d=1时,等价为图3a的卷积操作对视频帧进行逐帧处理,但是并没有利用到前后帧的运动信息。当d=L时,它的效果等同于图3b。所以当d小于L时,三维卷积能更可控的利用运动信息——如果我们想让运动信息消失的快一些,就调大三维卷积的深度d。相反,使用小一些的d能更缓慢的提取运动信息。

图3. 二维与三维卷积操作示意图
在此基础上,我们设计了自己的视频质量评估算法C3DVQA。其核心思想是使用三维卷积来学习时空联合特征,进而更好的去刻画视频质量。
图4给出了我们所提出的网络结构图,其输入为损伤视频和残差视频。
网络包含两层二维卷积来逐帧提取空域特征。经级联后,空域特征仍保留前后帧的时许关系。网络接着使用四层三维卷积层来学习时空联合特征。
在这里,三维卷积输出描述了视频的时空掩盖效应,而且我们使用它来模拟人眼对视频残差的感知情况:掩盖效应弱的地方,残差更容易被感知;掩盖效应强的地方,复杂的背景更能掩盖画面失真。
网络最后是池化层和全连接层。池化层的输入为残差帧经掩盖效应处理后的结果,它代表了人眼可感知残差。全连接层学习整体感知质量和目标质量分数区间的非线性回归关系。
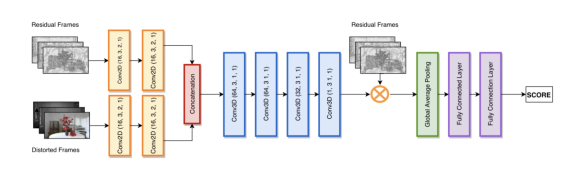
图4. 本文所提出的网络结构图。包含两层二维卷积,四层三维卷积,池化和全连接层。卷积参数表示:(channel,kernel size,stride, padding)
我们在LIVE 和CSIQ 两个视频质量数据集上对所提出算法的性能进行验证。LIVE数据库包含10个参考视频和对应每个参考视频的15个失真视频。CSIQ数据集包含12个源视频和相对应的18个失真视频。我们使用标准的PLCC和SROCC作为质量准则来比较不同算法的性能。
因为这两个数据库相对较小,我们参考另外一**深度学习文章 [10] 的做法,每次随机抽取80%的参考视频和由它们所得到的失真视频作为测试集。我们重复了20次这样的数据集划分并且每次都从头开始训练模型。具体质量评估的散点图如图5所示。
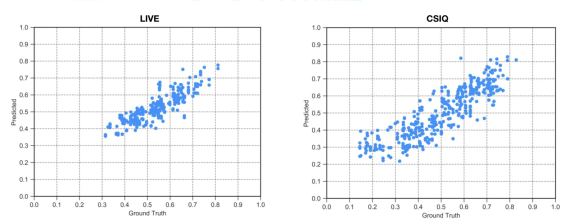
图5. 质量估计结果散点图,每一个点代表一个待测视频。其中Y轴为估计视频质量,X轴为主观打分结果,左图为LIVE上测试结果,右图为CSIQ上测试结果。
我们与常用的全参考质量评估算法进行了对比,比较的算法包括PSNR,MOVIE [11],ST-MAD [12],VMAF和DeepVQA [10]。每次测试都**得到一个PLCC和SROCC,下表中我们使用多次实验结果的中值来代表最终性能。
我们可以清楚的看到本文所设计的算法C3DVQA在两个数据库上均大幅领先PSNR,MOVIE,ST-MAD,VMAF等传统算法。值得一提的是DeepVQA也是一个基于深度学习的算法,也取得了不错的性能。我们把这些性能提提升归结为两方面的原因:
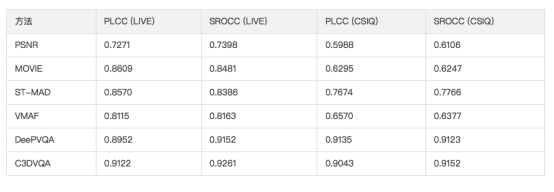
表1. LIVE和CSIQ两个数据库上不同全参考算法性能比较
本文简要回顾了目前学术界和工业界视频质量评估方向的发展状况。出于复杂度考虑,工业界仍倾向于使用复杂度较低的基于图像质量评估的方案。但是这样做的缺陷就是不能不能把视频作为一个整体来学习时空特性,尽管结果差强人意,也算是性能与复杂度很好的折中。
我们提出了一种基于三维卷积神经网络的全参考算法。通过学习视频的时空联合特征,能更好的解决运动信息丢失问题。相对于传统特征提取算法,我们的算法能大幅度的提升准确度。
当然,这一切才刚刚开始,还有很多工作需要补充。我们想要详细的复杂度分析,特别是在没有GPU可用的场景。我们也想知道所训练的算法在其它数据库上的性能,而且不仅仅局限于PGC视频,也包括UGC视频。
好消息是我们有计划对业界开源模型训练代码,这样能方便所有人去使用自己的数据库训练测试特定视频业务场景。同时,我们也欢迎任何形式的协同开发,不管是贡献数据库,还是贡献预训练模型,甚至是抛出业务场景中所遇到的问题。
本项目基于**多媒体实验室与北大深圳研究生院李革教授团队高校联合项目。
本文由 @**产业互联网 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议
