时间: 2021-08-03 09:17:48 人气: 22 评论: 0
上一文《如何用咨询公司的“套路”构建策略?(一)》我们分享了需求分析、确定目标和手段的方法。下面我们继续探讨如何学习咨询公司的“套路”构建具体策略。

我们的策略都是基于业务问题之上构建的,首先,我们当然需要去做需求收集、用户访谈,但同时也需要去大胆质疑,此外,我们还需要拓展思维边界,穷尽各种可能性。
这里,我们要提到的是麦肯锡的另一个显性知识——MECE原则,所谓的MECE(Mutually Exclusive Collectively Exhaustive)指的是“相互独立,完全穷尽”,具体而言,就是在做分析时列出解决方案的各项内容,并保证每一项内容都是独立的,不存在包含或交叉的关系。此外,要想到所有可能的内容,不要遗漏,保证穷尽。
MECE原则听上去非常简单,但越是听上去简单的方法,在使用时越难操作,这就像大道理一样,听着都对,但知道了这么多道理,却仍然过不好这一生。
其实MECE的正确顺序应该是“完全穷尽”、“相互独立”,其中,“相互独立”无非就是在归类时把相似的内容放到一起,保证各个分类相互独立,而真正的难点在于如何做到“完全穷尽”。
大多数时候我们都是做不到“完全穷尽”的,每个人都有自己的认知边界,也许我们已经绞尽脑汁,想出了自认为足够详尽的方案了,但当那些提升认知甚至颠覆认知的新观点出来时,我们才深感自己的脑洞之狭窄。
那么,我们应该怎么办呢?
因为每个人都有认知局限,所以,为了打破局限,拓宽认知边界,我们就需要去向更多的人请教。
首先,我们自然需要去请教那些离业务最近的人,一切策略都应该从业务中来,但在挑选访谈对象时,我们应该对他们有一些大致的了解。总体而言,我们至少应该在小白、老手、领导这几类人中各选几个进行沟通。
其次,我们需要去请教行业大咖,这些行业大咖经验丰富,他们可能出身业务,但视野**高于业务,如果身边有这样的专家当然最好,如果没有的话,那么可以去看大咖写的书,书中**有他们的中心思想。
但是不要仅仅只看某一个大咖的书,看一个人的书或是同类观点的书,往往容易产生可得性偏见,拿着观点当事实。最好是选择观点有很大差异的多个人的书,至少,他们的观点是“相互独立”的。
不过,大咖的观点都是基于自己多年的经验,难免**有经验主义的影子。所以,我们还需要通过资讯或论文去了解最前沿的研究,在挑选论文时可以重点看那些做案例研究的论文,因为这类论文研究的都是最新的个例,往往可能**新你的认知,而做实证研究的论文反映的大多是普遍规律,可以作为看书的补充。
项目管理的五大元素中就有一项——范围,也就是事的边界,如果不能确定事情的边界,就不可能做到所谓的“穷尽”。
在上一篇文章中讲到过确定手段的方法,一方面是基于业务的需求和经验,另一方面,还要借助于数据进行分析验证。
首先,是验证所选的手段确实能有效影响目标,之前提到过可以观察变量之间的相关性。
其次,针对我们脑暴出来的想法进行验证,我们在头脑风暴、定性访谈中得到的想法可能五花八门,为了“穷尽”,我们榨出了所有能想到的可能性,但并不是所有的想法都要去实施或者能实施的,因此我们在实施之前应该进行想法的初步验证。
举个例子,以“人人都是产品经理”这个平台的付费课程推荐为例,假如现在有一门新课叫“产品设计从入门到精通”,我们假设浏览产品设计类文章比较多的用户应该都**感兴趣,那么在做推荐之前,我们可以先做一个验证。
我们通过数据分析发现,浏览产品设计类文章相比其他类型文章更多的用户,之前购买产品设计类课程的比例并没有其他课程高,那么说明浏览产品设计类文章这个标签和购买产品设计类课程的意愿之间没有直接联系,可能只是因为平台上产品设计类的文章更多而已。
再比如,我们假设电商促销活动带来的增量中,有很大一部分是对未来需求的透支,但通过数据我们发现,在促销活动结束后,销量只是跌回促销前的平均水平,并没有明显的透支现象,那么在后续分析时,可以忽略透支效应的影响。
按照类似的方法,我们**否决一些观点,也验证了一些假设,在这个过程中不断明晰此次研究的边界。
人工智能说来很火,究其本质其实就是一整套算法的融合,不管是传统的机器学习算法还是深度学习,人工智能最终都是人类巧妙运用算法“呆板”的原则来解决现实问题的方法。
在完成业务建模之后,我们已经明确了要研究的具体问题和大致方案是什么了,那么接下来的工作就是将人话翻译成机器语言。
在进行算法建模之前,我们先要理解算法的本质。算法的本质其实是在一定条件下,基于固有原则,将有限的输入模式化输出为结果的过程。这个定义是我自己瞎编的,由于不是算法出身,所以只能基于自己的理解来做分享。
下面我们就结合算法的定义,来概括一下算法建模的步骤:
首先,为什么说是“在一定条件下”,因为任何算法都有自己的前提假设,比如运用回归模型的前提是不能存在多重共线性,而岭回归除外,使用分类决策树的前提是变量必须是离散的等等,因此我们完成业务建模后,需要由算法工程师协助进行算法模型的初筛,看一下哪些模型可以适用于当前场景。
“固有原则”是算法在理性方面优于人的重要原因,因为每一个算法都有不变的核心原则,他们**坚定原则并严格执行。人类虽然更加灵活变通,但也意味着人类很难坚持自己的原则,那么在复杂性极高的现代社**,人类就很难规避非理性因素,去找到本质的原理。
但是,算法正因为有其原则,所以必然存在局限性,那么我们需要做的就是进行算法的优劣势对比。
就拿随机森林和GBDT来比较,随机森林训练速度更快,且不用做特征选择,但是缺点是在噪声较大时容易出现过拟合。而GBDT的预测准确度更高,但并行计算难度大,且对异常值非常敏感。
在做具体的算法适配时一方面是基于现有的数据类型和数据质量,比如存在很多异常值的情况下,随机森林的效果**优于GBDT;另一方面,可以用数据效果说话,用多个模型同时做训练,最后评估各个模型的拟合效果,择优选择。
此外,我们甚至可以将场景进一步细分,然后进行模型组合,而要做到这一步就要求策略产品经理懂各类模型的原理和适用范围。比如:我们做老品的销量预测时,因为历史数据足够丰富,所以选用随机森林的效果**更好,可以更准确预测在当前的季节、价格和流量下的销售情况。
而对于新品或新的促销形式,由于缺失数据,我们无法通过在历史情形下的表现来预测销量,因此可以选择同类商品的数据进行回归模型拟合,从而预测新品或新促销形式下的销售状况。
“有限的输入”指的是数据的有限性和特征的有限性,数据越多、特征越多,那么对应的计算量就**越大,因此很多时候我们需要在准确性和可行性之间做平衡。
数据的有限性很好理解,下面重点讲一下特征工程。
特征工程指的是从原始数据中最大限度提取出特征的工程,说白了就是从现实中抽象出一个又一个的标签来进行计算。
我们在构建对于一个人的印象时,也是习惯于简化认知,给对方贴上各种的标签,对于计算机而言,同样也是基于类似的标签进行学习、计算,然后形成自己的模型,只不过计算机的认知维度更高,它能处理更多维度的数据。
初期的特征选取是严格基于业务建模的,基于对业务的理解,我们对特征的重要程度**有初步的判断,在服务器资源有限的情况下,我们可以基于重要的特征进行模型拟合,之后再逐步加入其它特征。
“模式化”指的是算法模式的固定性,现在已经有很多平台开发出了建模的应用软件,软件中集成了很多模块化的算子,即使不懂算法,只要知道输入的内容和输出的结果的意义,分分钟可以上手建模。
那么,算法工程师的价值何在呢?
算法工程师日常有很多工作其实是在做算法调参,算法虽然是模式化的,但仍然需要通过参数的调整去进行模式微调,这个工作就需要依靠工程师的“手艺”了。
此外,算法工程师最大的价值还在于做算法改造,当工程师对算法的原理、内部数学构造都了如指掌之后,就可以进行改造和优化了,这就好比是钟表匠,带着放大镜在每一个精密的零件上进行修改。
模型拟合完成之后,通过效果评估的指标数据,可以了解到模型的拟合效果。具体的指标不做赘述,但一定要在模型拟合后进行测试验证,防止模型过拟合。
我们可以拟合多个模型进行比较,最终选取效果最好的模型,或是进行模型的组合使用,对于效果不佳的模型可以返回上一步进行调参或是改造。
人和动物最大的差别在于**制造和使用工具,而工具对于人有两方面的意义,一类工具是对人类现有能力的增强,比如望远镜是对视力的增强、电话是对听力的增强、武器是对臂力的增强。
除此以外,还有另一类工具,比如测谎仪,熟悉测谎仪工作原理的朋友都知道,测谎仪并不一定能准确反映出一个人是否说谎,它只能记录人在情绪有波动时的生理变化,测谎过程中最关键的还是测谎专家提出的问题。
首先,测谎专家**先问一些基础问题,这样做的目的是为了建立基线,从而观察一个人在正常状态下的生理指标。
接着,测谎专家**问一些核心问题,很多时候他们**直接说答案,让嫌疑人回答是或否,那么当说到正确答案时,嫌疑人自然而言**因为紧张而引起情绪波动。
由此可见,测谎仪并不能直接测谎,而是更多依赖于人的经验判断,我们经常在美剧中看到这样的场景,一些有经验的嫌疑人**刻意在一些基础问题上撒谎,以此来干扰基线的评测,也就是说测谎仪这个工具同时还可能作为嫌疑人骗过警察的工具。
既然测谎仪如此不靠谱,那么为什么破案时还是**广泛使用呢?原因就在于,测谎仪提供了一个侦破案件的参考维度,它不能直接告诉我们真相,但能辅助我们去找到真相。
同样,招聘过程一般**经历简历筛选、笔试、面试等多个环节,其中HR在筛选简历时,**看应聘者的文凭、证书、成绩,这些都是了解面试者的工具。而面试时往往**面试多轮,甚至跨部门交叉面试,其目的就是从多个角度来全面评估应聘者的能力。
对于我们的模型而言,很多时候不一定能准确反映事实,但它提供了一个参考维度,当我们的模型足够完善之后,我们可以运用多个模型进行交叉验证,从而更准确地给出结论,同时也能不断丰富应用场景。
咨询公司的厉害之处除了制造工具以外,还在于**组合使用工具,麦肯锡的“金字塔原理”提供的即是组合各项论据证明结果的逻辑框架。
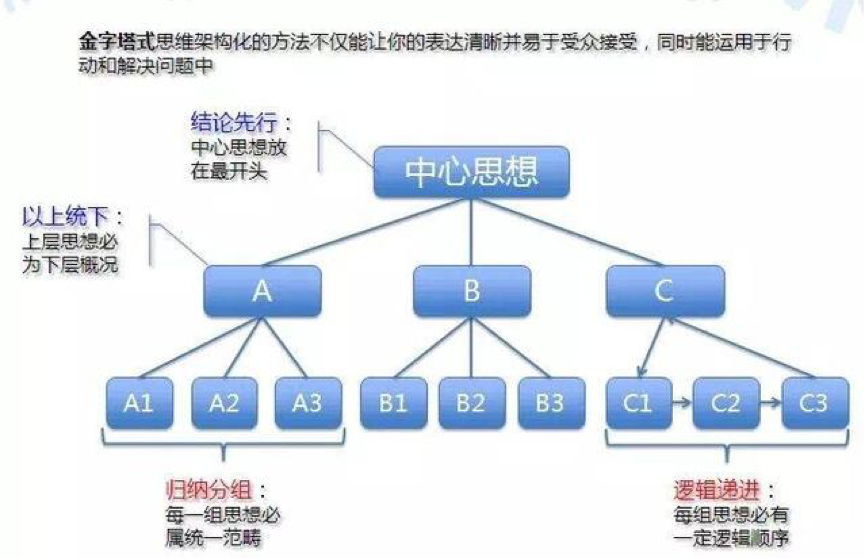
具体而言,金字塔原理的运用分为两步:
沿着金字塔的纵向路径,将要证明的中心结论进行逐层拆解细分,金字塔原理和杜邦分析最大的差别在于,金字塔原理是结论的整合梳理,而杜邦分析是拆解问题,从而找到症结。
金字塔原理认为中心论点可由三至七个论据支持,这些论据本身也可以作为分论点来列明,被三至七个论据支持,如此延伸下去,那么每一层的结论都可以拆解为下一层的论据。
比如:我们要构建市场选择策略,那么首先,应该定义什么市场是适合进入的,用户需求未被满足的市场?销售机**大的市场?垄断程度低的市场?竞争对手少的市场?还是符合品牌调性的市场?
接着,针对其中的每一项我们都需要有明确的标准,比如,如何证明垄断程度低?是不是可以用经济学里的市场集中度来计算(头部企业份额和),或是用HHI指数(所有企业份额的平方和)来反映?
如何证明用户需求未被满足?是不是可以通过舆情和调研等多种手段来分析?
单一的维度很难强有力地证明一项结论,因此,我们需要从多个角度去寻找论据。
比如:要证明市场机**大,第一,可以从整个市场的销售增长趋势来看;其次,可以看当前市场各商品的销量情况,如果商品不多且每个商品都卖的很好,那么说明还要较大的市场空间。
此外,还可以从用户的浏览行为来看,如果用户对该市场的关注度很高,但转化不高,那么一方面可能是价格原因,另一方面可能是当前市场的商品布局还不够丰富,因此可以加大投入力度。
任何套路都不可能完全套用,只有理解了套路的内核,才能见招拆招,化套路为神奇。
作者:Mr.墨叽,公众号:墨叽说数据产品
本文由 @Mr.墨叽 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
