时间: 2021-08-03 09:43:30 人气: 13 评论: 0

搜索引擎在我们的日常生活中很常见,在各个领域都发挥着它独特的作用。那今天我们一起从文中来了解一下关于搜索引擎索引的这些概念。
索引其实在日常生活中是很常见的,比如:书籍的目录就是一种索引结构,目的是为了让人们能够更快地找到相关章节内容。再比如:像hao123这种类型的导航网站,本质上也是互联网页面中的索引结构,目的类似,也是为了让用户能够尽快找到有价值的分类网站。
在计算机科学领域,索引也是非常常用的数据结构,其根本目的是为了——在具体应用中加快查找速度。比如:在数据库中,在很多高效数据结构中,都**大量采用索引来提升系统效率。
具体到搜索引擎,索引更是其中最重要的核心技术之一,面对海量的网页内容,如何快速找到包含用户查询词的所有网页?倒排索引在其中扮演了关键的角色。
本文主要讲解与倒排索引相关的技术,通过引入简单实例,介绍与搜索引擎有关的一些基本概念,了解这些基本概念对于以后深入了解索引的工作机制非常重要。
单词-文档矩阵是表达两者之间所具有的一种包含关系的概念模型,图1展示了其含义,图1中的每列代表一个文档,每行代表一个单词,打对勾的位置代表包含关系。
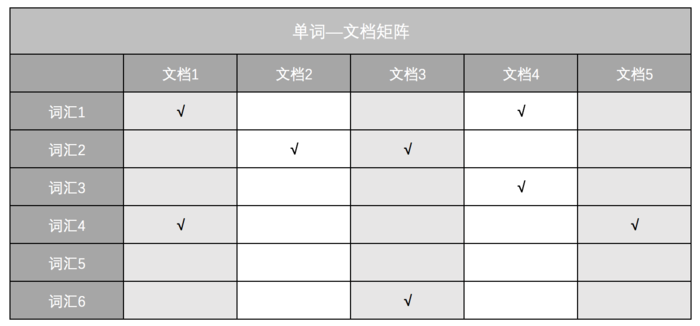
图1:单词-文档矩阵
搜索引擎的索引其实就是实现单词-文档矩阵的具体数据结构,可以有不同的方式来实现上述概念模型。比如:倒排索引、签名文件、后缀树等方式。
但是各项试验数据表明,倒排索引是单词到文档映射关系的最佳实现方式,所以本文主要介绍倒排索引的技术细节。
在这里向大家解释倒排索引常用的一些专用术语:
关于这些概念之间的关系,通过图2可以比较清晰地看出来:
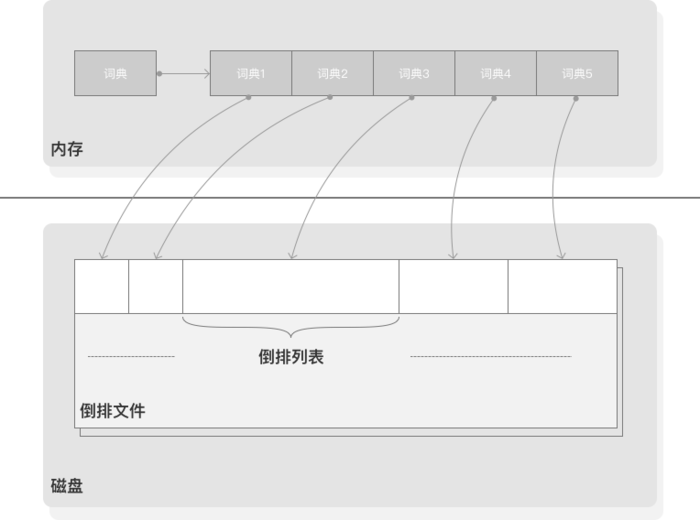
图2:倒排索引基本概念示意图
倒排索引从逻辑结构和基本思路上讲非常简单,下面我们通过具体实例来进行说明,使得大家能够对倒排索引有一个宏观而直接的感受。
假设文档集合包含5个文档,每个文档包含内容如下图所示:在图3中最左端一栏是每个文档对应的文档编号,我们的任务就是对这个文档集合建立倒排索引。
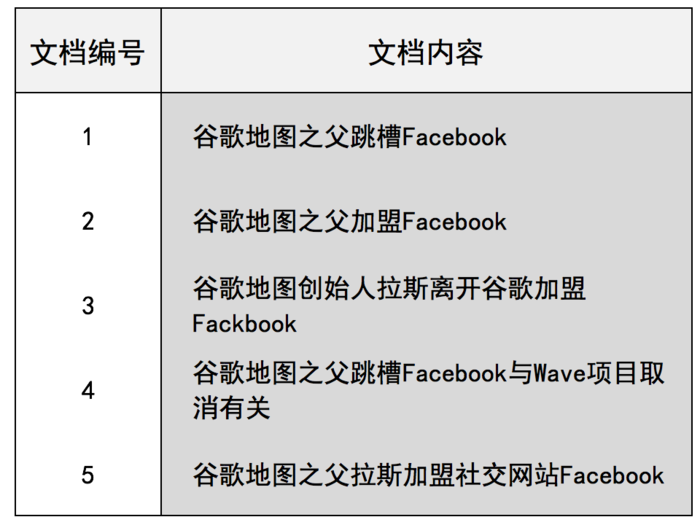
图3:文档集合
中文和英文等语言不同,单词之间没有明确的分隔符号,所以首先要用分词系统将文档自动切分成单词序列,这样每个文档就转换为由单词序列构成的数据流。
为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在处理结束后,我们可以得到最简单的倒排索引(参考图4)。
图4中,“单词ID”一列记录了每个单词对应的编号,第2列是对应的单词,第3列即每个单词对应的倒排列表。比如:单词“谷歌”,其中单词编号为1,倒排列表为{1,2,3,4,5},说明文档集合中每个文档都包含了这个单词。
之所以说图4的倒排索引是最简单的,是因为这个索引系统只记载了哪些文档包含某个单词。而事实上,索引系统还可以记录除此之外的更多信息。
图5是一个相对复杂些的倒排索引,与图4所示的基本索引系统相比,在单词对应的倒排列表中不仅记录了文档编号,还记载了单词频率信息,即这个单词在某个文档中出现的次数。之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是一个很重要的计算因子,所以将其记录在倒排列表中,以方便后续排序时进行分值计算。
在图5所示的例子里,单词“创始人”的单词编号为7,对应的倒排列表内容有(3;1),其中3代表文档编号为3的文档包含这个单词,数字1代表词频信息,即这个单词在3号文档中只出现过1次,其他单词对应的倒排列表所代表的含义与此相同。
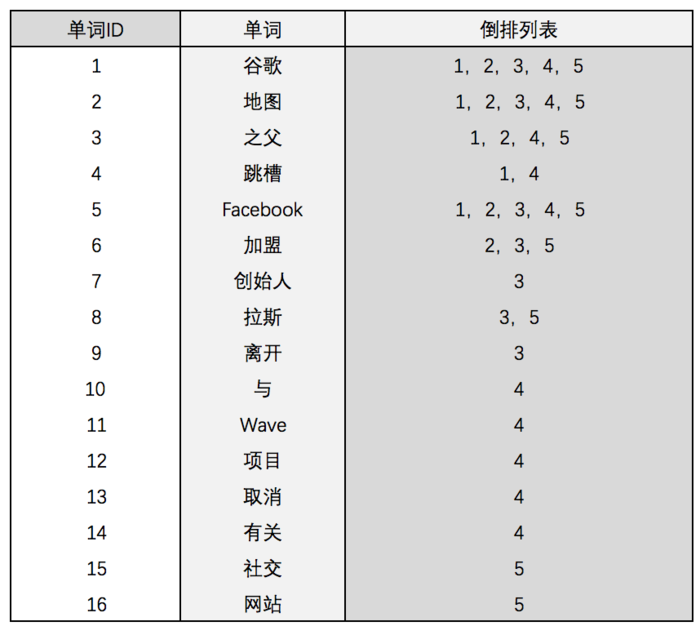
图4:最简单的倒排索引
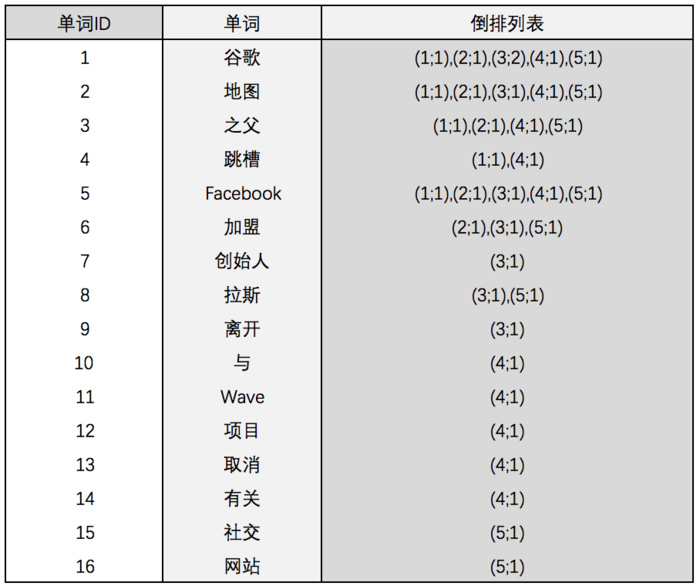
图5:带有单词频率信息的倒排索引
实用的倒排索引还可以记载更多的信息,图6所示的索引系统除了记录文档编号和单词词频信息外,额外记载了两类信息——即每个单词对应的文档频率信息(图6的第3列)及单词在某个文档出现位置的信息。
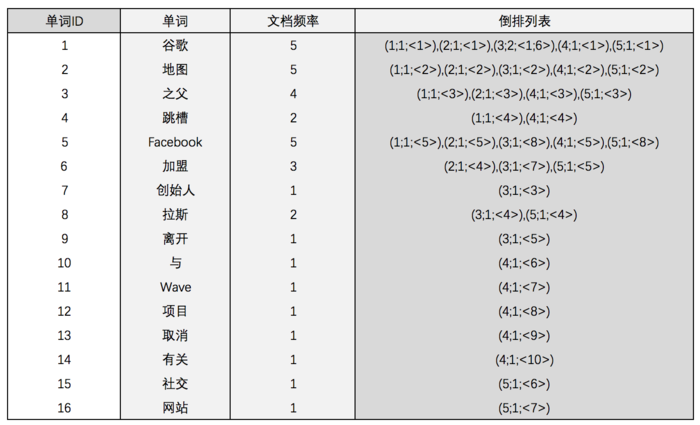
图6:带有单词频率、文档频率和出现位置信息的倒排索引
文档频率信息代表了在文档集合中有多少个文档包含某个单词,之所以要记录这个信息,其原因与单词频率信息一样,这个信息在搜索结果排序计算中是一个非常重要的因子。
而单词在某个文档中出现位置的信息并非索引系统一定要记录的,在实际的索引系统里可以包含,也可以选择不包含这个信息,之所以如此,是因为这个信息对于搜索系统来说并非必要,位置信息只有在支持短语查询的时候才能够派上用场。
以单词“拉斯”为例:其单词编号为8,文档频率为2,代表整个文档集合中有两个文档包含这个单词,对应的倒排列表为{(3;1;<4>),(5;1;<4>)},其含义为在文档3和文档5出现过这个单词,单词频率都为1,单词“拉斯”在这两个文档中的出现位置都是4,即文档中第4个单词是“拉斯”。
图6所示的倒排索引已经是一个非常完备的索引系统,实际搜索引擎的索引结构基本如此,区别无非是采取哪些具体的数据结构来实现上述逻辑结构。
有了这个索引系统,搜索引擎可以很方便地响应用户的查询。比如:用户输入查询词 “Facebook”,搜索系统查找倒排索引,从中可用读出包含这个单词的文档,这些文档就是提供给用户的搜索结果。
而利用单词词频信息、文档频率信息即可对这些候选搜索结果进行排序,计算文档和查询的相似性,按照相似性得分由高到低排序输出,此即为搜索系统的部分内部流程。
本文由 @kevin 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CCO协议
