时间: 2021-08-03 09:50:00 人气: 9 评论: 0

本文主要从5大方面具体介绍了现在行业内对语音交互系统的常见评价指标,分别是语音识别、自然语言处理、语音合成、对话系统和整体用户数据指标。enjoy~
最近,在饭团“AI产品经理大本营”里,有团员提问:如何制定针对自然语言语音交互系统的评价体系?有没有通用的标准?例如在车载环境中,站在用户角度,从客观,主观角度的评价指标?
上周,我在专属微信群内抛出了这个问题,当晚,胡含、我偏笑、艳龙等朋友就分享了不少干货心得;最近几天,在飞艳同学的协助整理下,我又补充了一些信息,最终形成这篇文章,以飨大家。
语音识别(Automatic Speech Recognition),一般简称ASR,是将声音转化为文字的过程,相当于人类的耳朵。
看纯引擎的识别率,以及不同信噪比状态下的识别率(信噪比模拟不同车速、车窗、空调状态等),还有在线/离线识别的区别。
实际工作中,一般识别率的直接指标是“WER(词错误率,Word Error Rate)”
定义:为了使识别出来的词序列和标准的词序列之间保持一致,需要进行替换、删除或者插入某些词,这些插入、替换或删除的词的总个数,除以标准的词序列中词的总个数的百分比,即为WER。
公式为:
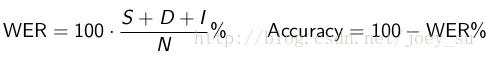
3点说明:
先需要介绍下语音唤醒(Voice Trigger,VT)的相关信息。
(1)语音唤醒的需求背景
近场识别时,比如使用语音输入法时,用户可以按住手机上siri的语音按钮,直接说话(结束之后松开);近场情况下信噪比(Signal to Noise Ratio, SNR)比较高,信号清晰,简单算法也能做到有效可靠。
但是在远场识别时,比如在智能音箱场景,用户不能用手接触设备,需要进行语音唤醒,相当于叫这个AI(机器人)的名字,引起ta的注意,比如苹果的“Hey Siri”,Google的“OK Google”,亚马逊Echo的“Alexa”等。
(2)语音唤醒的含义
简单来说是“喊名字,引起听者(AI)的注意”。如果语音唤醒判断结果是正确的唤醒(激活)词,那后续的语音就应该被识别;否则,不进行识别。
(3)语音唤醒的相关指标
以上a、b、d相对更重要。
(4)其他
涉及AEC(语音自适应回声消除,Automatic Echo Cancellation)的,还要考察WER相对改善情况。
自然语言处理(Natural Language Processing),一般简称NLP,通俗理解就是“让计算机能够理解和生**类语言”。
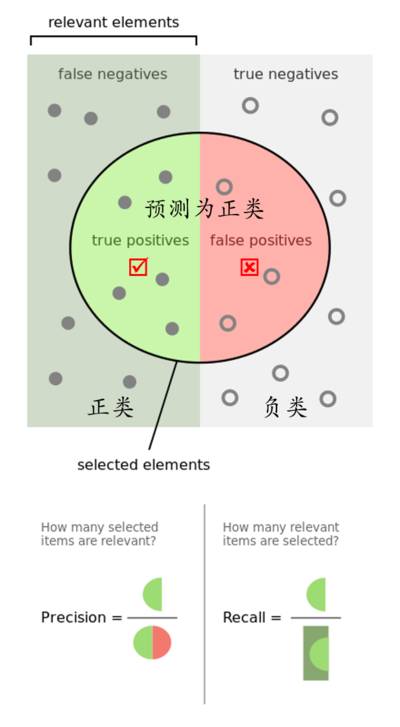
1、准确率、召回率
附上之前文章《AI产品经理需要了解的数据标注工作入门》中,分享过的一段解释:
举个栗子:全班一共30名男生、20名女生。需要机器识别出男生的数量。本次机器一共识别出20名目标对象,其中18名为男性,2名为女性。则
再补充一个图来解释:
2、F1值(精准率和召回率的调和平均数)
模型调优后追求F1值提升,准确率召回率单独下降在一个小区间内,整体F1值的增量也是分区间看(F1值在60%内,与60%以上肯定是不一样的,90%以上可能只追求1%的提升)。
P是精准率,R是召回率,Fa是在F1基础上做了赋权处理:Fa=(a^2+1)PR/(a^2P+R)
语音合成(Text-To-Speech),一般简称TTS,是将文字转化为声音(朗读出来),类比于人类的嘴巴。大家在Siri等各种语音助手中听到的声音,都是由TTS来生成的,并不是真人在说话。
主观测试(自然度),以MOS为主:
客观测试:
对话系统(Dialogue System),简单可以理解为Siri或各种Chatbot所能支持的聊天对话体验。
(1)比如智能客服,如果这个Session最终是以接入人工为结束的,那基本就说明机器的回答有问题。或者重复提供给用户相同答案等等。
(2)分专项或分意图的统计就更多了,不展开了。
比如用户完成一个任务的耗时、回复语对信息传递和动作引导的效率、用户进行语音输入的效率等(可能和打断,One-shot等功能相关);具体定义,各个产品自己决定。
(1)闲聊型
(2)任务型
(3)问答型
整体来说,行业一般PR宣传时,**更多的提CPS。其他指标看起来可能相对太琐碎或不够高大上,但是,实际工作中,可能CPS更多是面向闲聊型对话系统,而其他的场景,可能更应该从“效果”出发。比如,如果小孩子哭了,机器人能够“哭声安慰”,没必要对话那么多轮次,反而应该越少越好。
目前对于这类问题,一般是使用人工评估的方式进行。这里的语料,通常不是单个句子,而是分为单轮的问答对或多轮的一个session。一般来讲,评分范围是1~5分:
另外,为了消除主观偏差,采用多人标注、去掉极端值的方式,是当前普遍的做法。
常规互联网产品,都**有整体的用户指标;AI产品,一般也**有这个角度的考量。
1、DAU(Daily Active User,日活跃用户数,简称“日活”)
在特殊场景**有变化,比如在车载场景,**统计“DAU占比(占车机DAU的比例)”。
2、被使用的意图丰富度(使用率>X%的意图个数)。
3、可尝试通过用户语音的情绪信息和语义的情绪分类评估满意度。
尤其对于生气的情绪检测,这些对话样本是可以挑选出来分析的。比如,有公司**统计语音中有多少是骂人的,以此大概了解用户情绪。还比如,在同花顺手机客户端中,拉到最底下,有个一站式问答功能,用户对它说“怎么登录不上去”和说“怎么老是登录不上去”,返回结果是不一样的——后者,系统检测到负面情绪,**提示转接人工。
本篇分享,介绍了现在行业内对语音交互系统的常见评价指标,一方面,是提供给各位AI产品经理以最接地气的相关信息;另一方面,也是希望大家基于这些指标,打造出更好的产品体验效果。
**钊(hanniman),图灵机器人-人才战略官,人人都是产品经理专栏作家,前**产品经理,微信公众号/知乎/在行/饭团“hanniman”。5年人工智能实战经验,8年互联网行业背景。“人工智能产品经理”概念的推动者,被AI同行广泛传播的200页PPT《人工智能产品经理的新起点》的作者。关注人机交互(特别是语音交互)在手机、机器人、智能汽车、智能家居、AR/VR等前沿场景的可行性和产品体验。
本文原创发布于人人都是产品经理,未经许可,不得转载
