时间: 2021-08-03 10:06:42 人气: 14 评论: 0

这个产品行不行啊,是不是伪需求?是不是市场不行?还是说产品模式不行,不能给用户带来实际价值?就这么几个运营相对较好的产品,是行业壁垒太高,还是产品没有收益啊?这4个你关心的问题,我将在这篇文章为你解答。
PM常**有向他人介绍你的产品的时候。当你回答淘宝,京东,百度,滴滴等具有标签化性质的产品时(广为人知的产品或模式,如电商,教育,P2P等),听者一定第一时间就能知道这个产品是干嘛的;但如果你做的是小众产品或是很垂直细分的产品,那估计你就需要花上一点时间介绍你的产品了(当然如果你根本不care他们是否需要了解这个的话,那就另当别论了)。
我做的就是一个新兴的细分产品——“大数据竞赛平台”,此产品在全球范围内兴起6年,国内兴起四年,当前处于市场探索期。
目前国际上比较出名的产品有一个,国内有四个,其他的都是要么死了,要么处于半死不活的状态(这里指国内的),这五个产品分别是:
相信这个时候你一定**说:这竞品数,竞赛数和用户数也都太少了,这个产品行不行啊,是不是伪需求?是不是市场不行?还是说产品模式不行,不能给用户带来实际价值?就这么几个运营相对较好的产品,是行业壁垒太高,还是产品没有收益啊?
我的回答是:
这四个答案绝对不是我强词夺理,凭空捏造的,下面让我逐一说明。
慢修我,喜欢叫它“数据科学竞技场”:一个通过举办竞赛,汇集“数据科学家”为企业和组织机构解决数据科学相关技术难题的众包平台。
产品模式是一种存在特殊性的C2B模式:与常规的C2B模式产品相同的是,该产品也是C端用户借助平台获取需求;不同点在于,用户需依托平台完成对B端用户的服务,这也是该产品的特殊性所在。
原因在于“大数据”这三个字:
这要求产品技术团队具有较高的数据分析,数据处理,模型算法处理能力。这就给产品带来了较高的技术门槛,而很多技术团队水平不达标的产品,只能走向死路。这也是为什么现存的产品都具有技术背景和学术背景的共性原因。
这个技术门槛也同样影响着需求频次和需求总量。
首先,从实际情况看,借助平台举办竞赛的B端用户,多为大中型企业(如:通用汽车,亚马逊,阿里,京东,国家电网等)因为他们具有庞大的数据量,再或者是从事大数据相关领域的企业(如:人像识别,自动驾驶,职能语音,机器学习等)。
其次,借助平台决绝的需求,大多存在较高的技术难度(技术难度不高,企业内部早就解决了),而具有一定技术难度的需求从总量和频次两个维度上看都比较较低。
最后,“数据”一直是各个企业最敏感的东西,很多企业出于各种原因不愿意将数据对外开放。
综合上述三点的原因,致使市场处于“需求总量少,需求频次低”的现状。各竞赛平台举办的竞赛数正印证了这一点。
技术门槛也造成了C端用户基数较低,并且增速缓慢情况:
上述四点要求,决定了用户基数较低,且增速缓慢的现状。各竞赛平台的注册用户数也印证了这一点,这其中还包括同一个用户注册多个平台,并且在一个平台拥有多个**的情况。
从上述情况看,当前市场确实是不行,但是这不**是常态,而未来的市场一定**越来越大,这一定是个增量市场。
原因在于,我们正处于大数据时代,随着相关技术知识的普及和应用技术(广度)的不断提升,技术需求量和技术人员基数也**不断增长,所以未来它一定是个增量市场,只是增量有多大还需要我们进一步印证。
依据易观智库发布的《中国大数据市场年度综合报告2016》显示,2015年中国大数据市场规模达到105.5亿元,同比增长39.4%,预计未来3~4年,市场规模增长率将保持在30%以上。整体市场总量庞大,且增速较快。
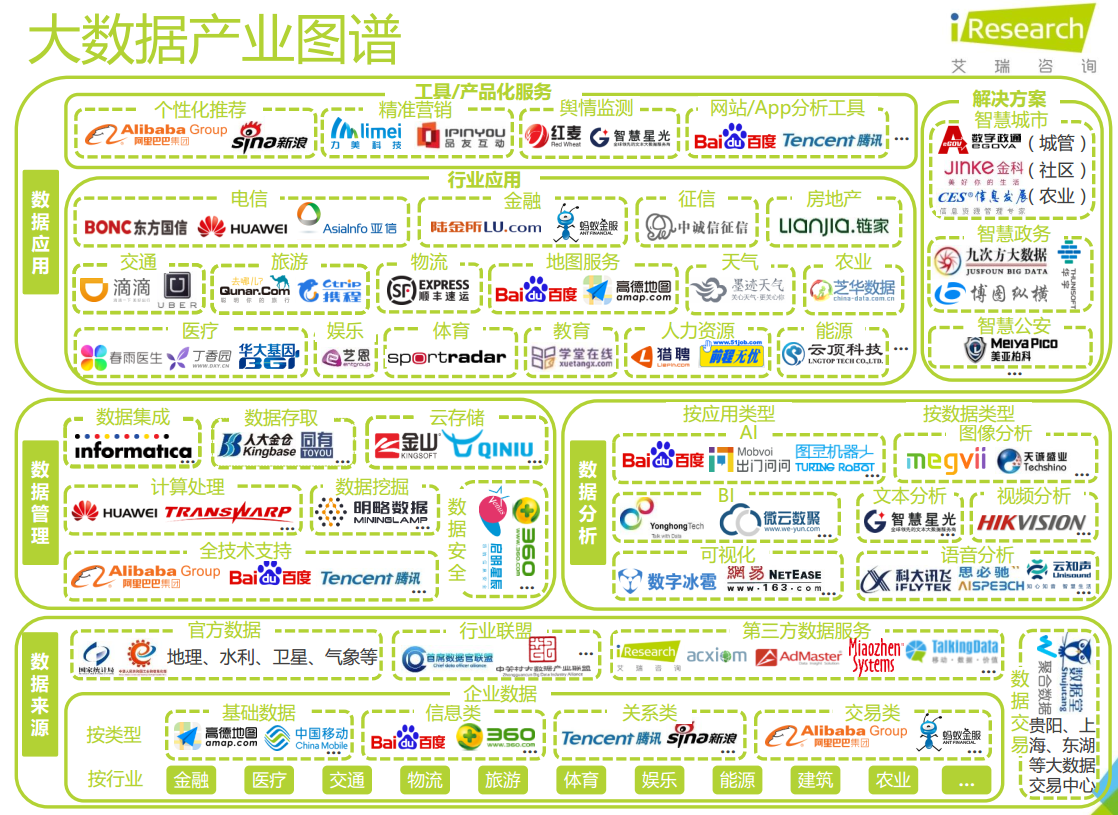
源自:艾瑞网《2016年中国数据驱动型互联网企业大数据产品研究报告》
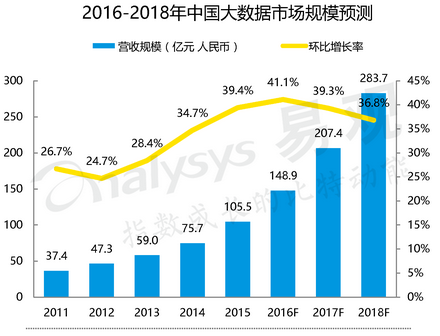
源自:易观智库<中国大数据市场年度综合报告2016>
图谱中显示的企业只是现今乃至未来整个大数据行业企业总量的冰山一角,但他们其中已为市场提供了20+个赛题(占图谱企业数的20%)。按照2016~2018年时候藏需求的增长度推算,这些企业**为市场至少提供38个以上的赛题数。
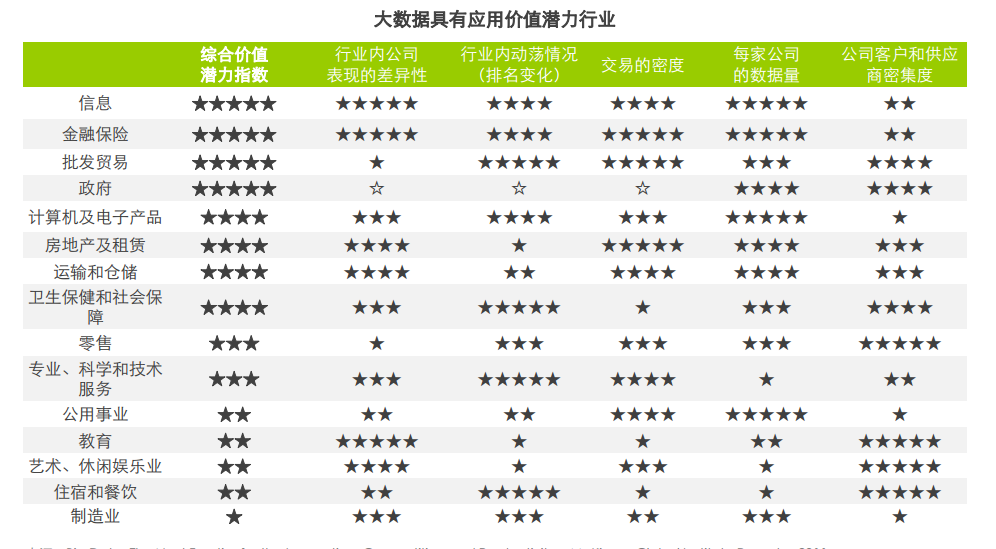
来源,Big Data: The Next Frontier for the Innovation, Competition and Productivity – McKinsey Global Institute Report,2011
图例中2011年预测的行业,目前都在广泛应用大数据科学技术,除此之外还包括:招聘,网游,服装等行业,而企业对技术的关注度也在提升。
源自:易观智库<中国大数据市场年度综合报告2016>
企业对大数据技术认可度的提升,使得很多大数据技术得到实际的应用。当前企业需求主要围绕,数据可视化分析,语音识别与语音分析,地理位置应用,精准营销,网站和移动数据分析,反作弊技术等,单着只是一部分。
而未来,十大热门行业均与数据科学技术惜惜相关,包括:AI与高级机器学习,智能应用,智能对象,VR与AR,数字孪生 ,区块链应用,**话系统,网格应用与服务体系构架,数据技术平台(信息系统、客户体验、分析与情报、物联网、企业生态系统),自适应安全构架等。
其中任一个行业都需要较高的技术需求,每一个技术需求的解决,都不是一个企业的单一技术团队能在短时间解决的,这需要几十个甚至上百个方案的反复推敲和测试,过程中需要大量的技术人员各抒己见,协同合作,进行高频,大规模的测试和运算。这就有对市场产生了很高的需求。
上文提到产品的技术门槛,将很多C端用户拒之门外(这也是行业本身的现状),但从人才供应量的变化上看,整个大数据相关行业的从业人员也在不断增加。
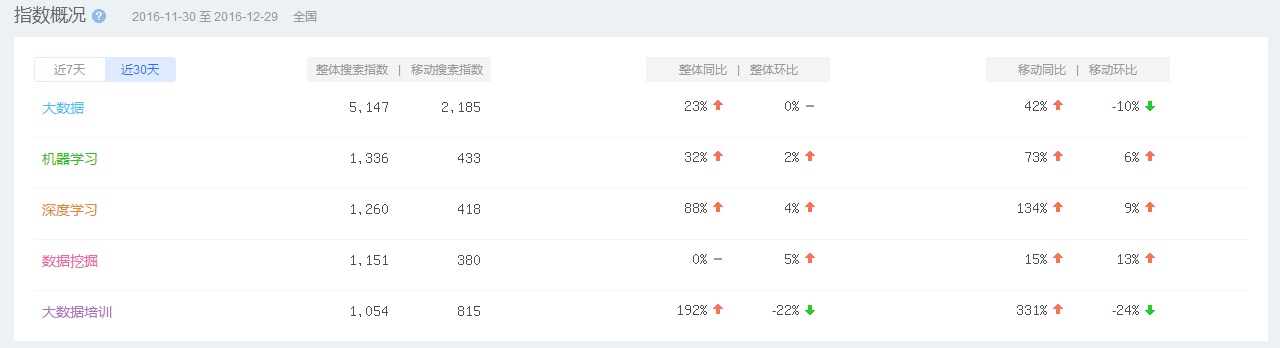

源自:百度指数 2011年~至今
依据百度指数的数据显示,“大数据”,“大数据”培训,大数据技术相关关键词的搜索度呈显大幅度增长趋势,这也验证了从行业到社**对相关领域的关注在不断提升。
首先市场有需求,就有学校和培训机构提供相关技术培训;市场有需求就有用户参与培训。抛开大学不提,我国光提供大数据技术培训的在线教育网站就不下百个,各网站报名参加授课的学员每年都不下千人(单一科目达不到这个数,平台根本生存不了)。以这样的增长趋势看,大数据技术相关人才正在逐步涌入市场。
其次,各大竞赛平台也在尽一切努力对用户进行技术培养。平台通过开放练习赛,给予参赛奖励的方式,鼓励用户锻炼提升自身的技术能力;在社区,通过鼓励用户分享经验贴,技术贴和开源代码的方式,提升用户的专业知识含量。利用这两种方式,加快用户从小白到专家的速度,也为大数据技术爱好者提供了更多的转化空间。毕竟每一个用户都是从小白变成专家的,从实际情况看,各平台每年新增用户数比例为10%~15%;用户中每年又有接近5%的用户成长为中高级“数据科学家”,这也为整个行业带来了一定技术人才的增长。(别小看这个比例,要知道行相关基础人才本身的基础也不高)
虽然技术人员呈现增长的趋势,但增速荣然缓慢,而与市场发展趋势(企业用人需求)相比较,依然是杯水车薪。
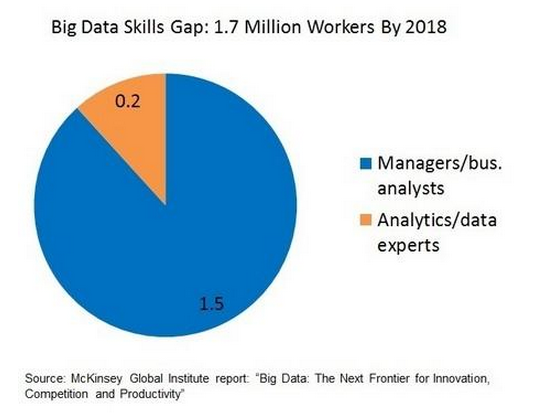
依据2014年麦肯锡提供的“大数据人才需求报告”,全球研究院的研究预测在未来6年,仅在美国本土就可能面临缺乏14万至19万具备深入分析数据能力人才的情况,同时具备通过分析大数据并为企业做出有效决策的数据的管理人员和分析师也有150万人的缺口。而我国在大数据岗位的需求上 上海是10万多,北京是15万多。
可见这是个强烈的供不应求的市场。
虽然从市场现状和人才供应量两个方面看,大数据竞赛平台这个产品的市场处于低沉状态。但是当前已经出现了,因为企业技术需求量远远大于人才供应量,而产生的强烈的供不应求的现状,也恰恰就是我们的机**。
众包模式的一项优点就是能帮助需求方解决人力不足,人才不足,技术水平不足的问题。而竞赛模式又在不断提升需求解决方案的质量。而我们的模式恰恰就有这样两点优势。
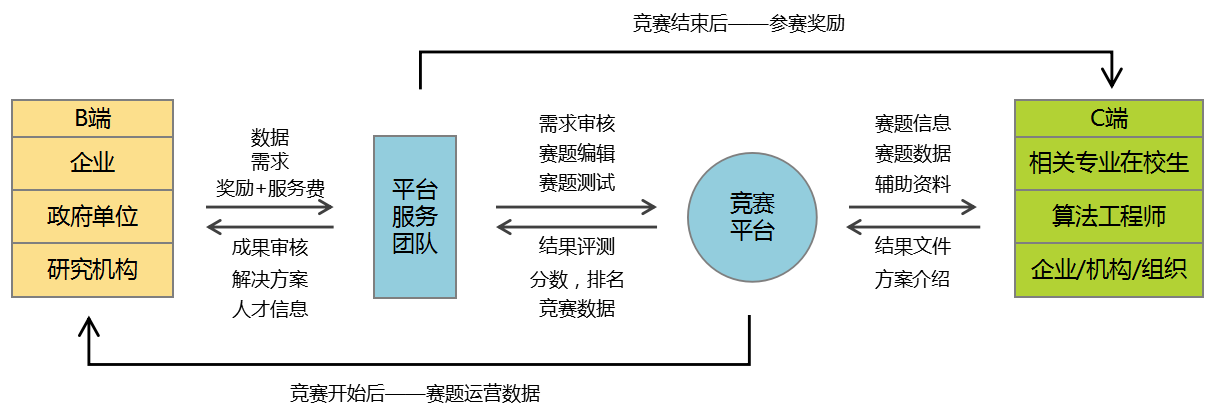
核心业务模式分析图
作为平台,我们并不是通常意义上的那种,做内容和资源交换的中介,我们是内容和资源的加工厂,帮助两个端口的用户更平衡,更高效,更精准的获取利益。
本产品可以大大降低企业和组织机构,在需求解决上投入的成本。同时解决由于资源不对称等其他原因产生的人才难获取,解决思路单一,开发周期过长,利益难平衡,专利限制,技术或行业壁垒庞大等问题。
接下来让我们借助企业自主解决需求和企业借助平台解决需求的两个流程,进行对比分析该模式对B端用户产生的价值。
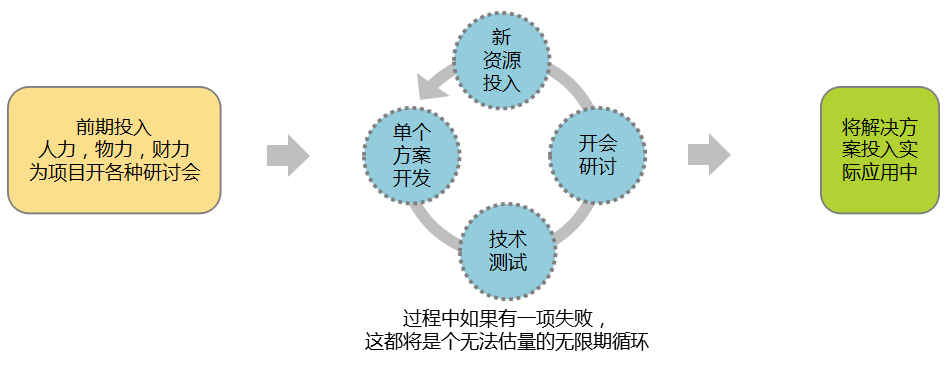
企业自主解决需求的流程

企业借助平台解决需求的流程
通过两种解决流程,我们可以对比出如下用户收益。
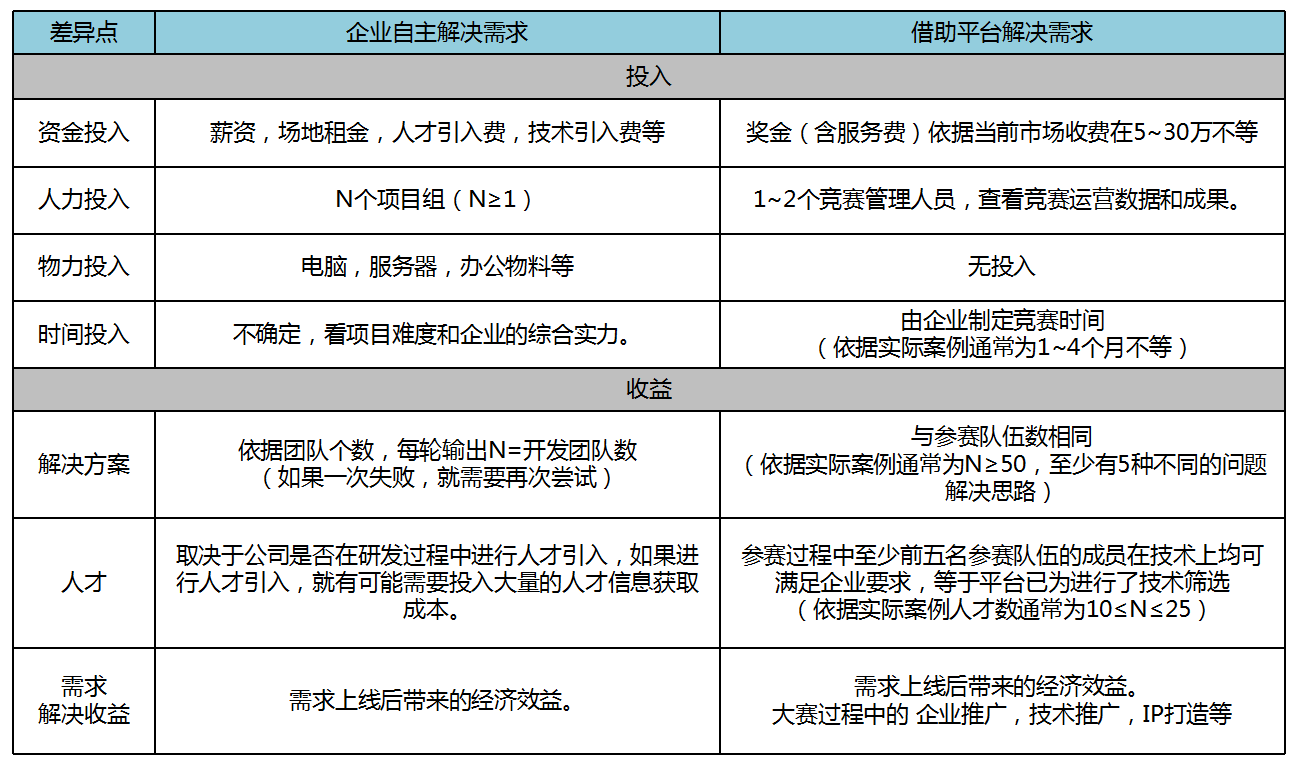
通过上述表格,可以很直观的对比出该产品为B端用户带来的价值,让我们采用产品价值分析法:用户价值=(新体验-旧体验)-换用成本,验证一下这个用户价值是否有意义。
需求解决赛:
用户价值=(相同时间内获得多个解决方案的体验 – 相同时间内获得1~2个解决方案的体验) – 换用竞赛平台的成本
备注:由于企业文化和团队文化的原因,企业自产的解决方案可能**出现思路趋同的情况
人才挖掘赛:
用户价值=(一次投入获得经过综合考验的人才的体验 – 反复多次投入获得未经过考验的人才的体验) – 换用竞赛平台的成本
备注:能够取得优异成绩的参赛者,都是相关技术的“专家”和高手,因此这批人具有能为企业带来无限价值的可能性。
举个实际案例进行说明:
好事达保险公司(Allstate)借助Kaggle举办了,通过“预测与汽车相关的伤害索赔情况,以便更精确地制定价格”的赛题。参赛者们根据2005年到2007年的数据(包括具体的汽车情况、以及每辆车相关的赔偿支出次数和数量)进行建模,并将它们应用到2008年至2009年的数据上。澳大利亚悉尼的保险精算顾问卡尔(Matthew Carle)提交的预测方案,精确程度比好事达保险公司的当前采用的技术 高出340%。
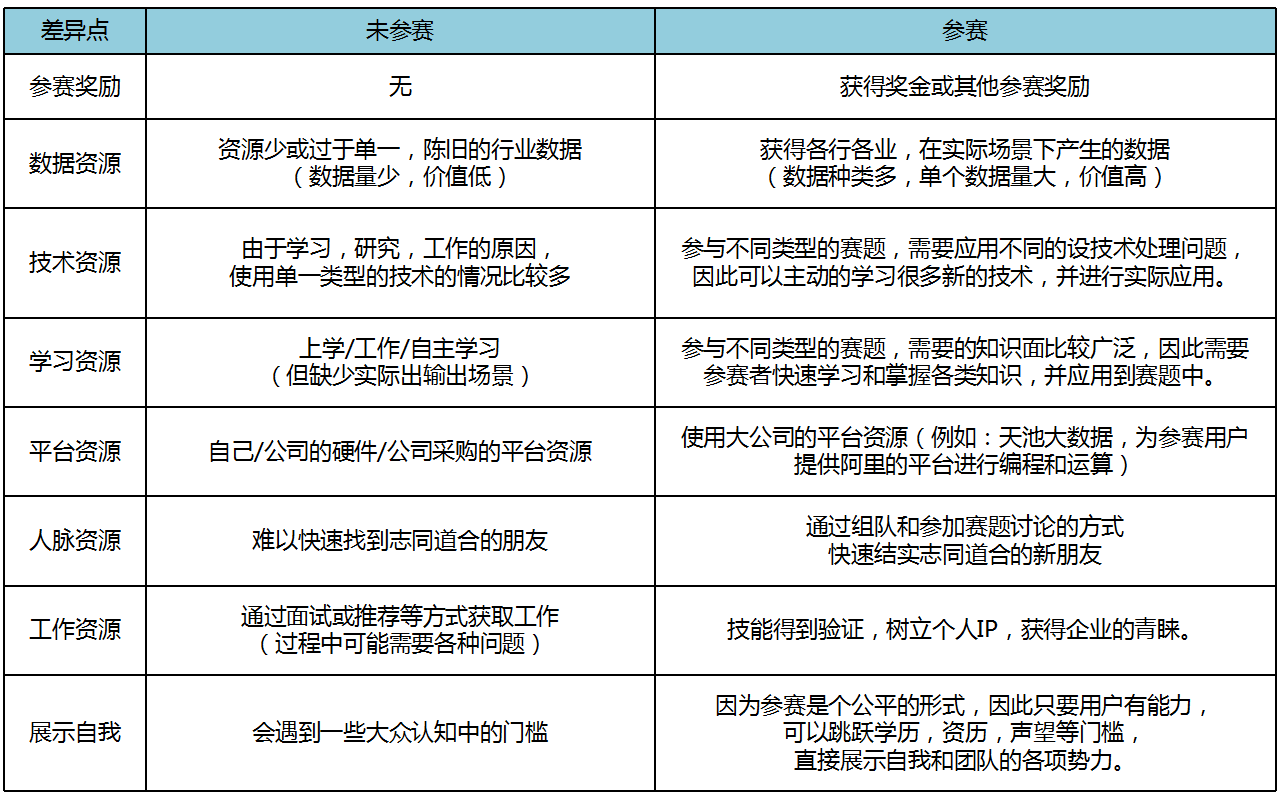
让我们继续采用产品价值分析法,验证一下这个用户价值是否有意义。
资源获取:
用户价值=(快速获得各类新鲜数据进行研究的体验 – 长期利用单一陈旧数据进行研究的体验) – 参加竞赛的成本
技术应用演练:
用户价值=(借助实际场景训练所学技术的体验 – 采用模式的场景锻炼所学技术的体验) – 参加竞赛的成本
优质工作:
用户价值=(通过简单直接的方式证明个人能力获得工作的体验 – 经历各种面试,忍受门槛歧视获得工作的体验) – 参加竞赛的成本
使用大数据竞赛平台的用户,可以源源不断的获取各种优势资源,借此提升自己的技术水平,增加所学知识的维度和深度,打造个人和团队IP,提升业内影响度。
举几个实际案例说明:
我们实现在短期内为用户产生价值收益的同时,也为我们带了大量的直接收益。
这还是个只要上线就能赚钱的产品,与其他互联网产品不同的地方在于,产品前期不需要投入大量的资金用于产品推广和流量获取,同时用户维护成本也很低。原因除了我们以上提到的市场现状和产品特点外,还因为产品自带的“负面”壁垒(还记得技术壁垒造成的市场现状吗)。
我们大多数的用户是在校大学生(计算机专业,处于大三及以上的学生,因为他们技术水平基本还能达标),在职的数据分析师,算法工程师,相关技术应用团队和企业(后三个占用户总数的30%)。这些用户除了大学生外,其他用户本身就**关注相关技术的动态,并主动希望借助平台获取资源,因此拉新成本较低。
而对于学生而言,因为各平台都有较强的学术背景和技术背景,这些背景的背后就是各大院校和研究机构的教授和大咖们,其中哪个人手下都有百十号的学生和团队,这就自然而然为平台引来了用户,更何况学生本身也对这种实际锻炼的机**垂涎欲滴。
综上,只要有足够的学术资源和媒体资源(有学术资源就有媒体合作,你懂的,又省去一个成本),产品就不需要进行多大推广,用户自己就来了。
同样,学术背景和技术背景也带来了大量的合作企业。
依据上文提到的,每个竞赛的时间周期为1~4个月,用户在这个过程中,需要每天进行编程和在平台上进行测试。也就是说用户在这个过程中,如果不是出现因成绩太差,时间不允许等原因产生退赛情况,那用户基本就黏在平台上了。因此只要竞赛的本身够棒,并且平台能保证新旧赛题之间的连续性。基本在用户维系上就不用下多大的功夫,有人管理竞赛,维护社区就行。
那么,“够棒”的竞赛从哪里来呢,这完全取决于平台自身的技术背景,学术背景和社**背景,三个背景缺少一点,企业都未必能和平台进行合作(不信你问问你老板,要是举办这样的竞赛,他**选择什么样的合作方。)这也就自然而然的屏蔽掉了其他竞品。而这也就是当前个大平台之间的竞争赛题资源的筹码。
OK,今天就到这,感谢你读到这里!!!
作者:慢修,微信公众号:慢修记事
本文由 @慢修 原创发布于人人都是产品经理。未经许可,禁止转载。
