时间: 2021-08-03 10:52:13 人气: 19 评论: 0

有的人觉得个性化推荐就是细分市场和精准营销,实际上细分市场和精准营销往往是把潜在的用户分成很多群体,这固然相比基于全体的统计有了长足的进步,但是距离“给每一个用户量身定做的信息服务”还有很大的差距,所以,只能说个性化推荐是细分市场的极致!实际上,信息服务经历了两次理念上的变革,第一次是从总体到群体,第二次是从群体到个体。第二次变革正在进行中,所要用到的核心技术就是这篇文章要讨论的个性化推荐技术。
有读者觉得个性化推荐就等同于协同过滤,这可能是因为协同过滤应用比较广泛并且比较容易为大众理解。实际上协同过滤只是个性化推荐技术中的一个成员。它与很多更先进技术相比,就好像流行歌曲和高雅音乐,前者广受欢迎,而且一般人也可以拿个麦克风吼两声,但是说到艺术高度,流行歌曲还是要差一些。当然,流行歌曲经济价值可能更大,这也是事实。总的来说,协同过滤只是个性化推荐技术中的一款轻武器,远远不等于个性化推荐技术本身。
图1:信息服务的两次变革:从总体到群体,从群体到个体。
有些读者可能不是很了解个性化推荐,我先推荐一些阅读的材料。中文的综述可以看我们2009年在《自然科学进展》上的综述。这篇文章质量不能说很好,但是可以比较快得到很多信息,了解个性化推荐研究的概貌。有了这个基础,如果想要了解突出应用的算法和技术,我推荐项亮和陈义合著的《推荐系统实践》。百分点科技出版过一本名为《个性化:商业的未来》的小册子,应用场景和商业模式介绍得比较细致,技术上涉及很少,附录里面介绍了一些主流算法和可能的缺陷,或许能够稍有启发。国外的专著建议关注最近出版的两本,其中实际上是很多文章的汇总,因为写这些文章的都是达人,所以质量上佳。Adomavicius和Tuzhilin的大型综述特别有影响力,不仅系统回顾了推荐系统研究的全貌,还提出了一些有趣的开放性问题——尽管我个人不是很喜欢他们对于推荐系统的分类方法。我们今年发表了一篇大综述,应该是目前最全面的综述,所强调的不仅仅是算法,还有很多现象和思路——大家有兴趣不妨看看。
有些读者认为个性化推荐技术的研究已经进入了很成熟的阶段,没有什么特别激动人心的问题和成果。恰恰相反,现在个性化推荐技术面临很大的挑战,这也是本文力图让大家认识的。接下来进入正题!我将列出十个挑战(仅代表个人观点),其中有一些是很多年前就认识到但是没有得到解决的长期问题,有一些事实上不可能完全解决,只能提出改良方案,还有一些是最近的一些研究提出来的焦点问题。特别要提醒读者注意的是,这十个挑战并不是孤立的,极有可能一个方向上的突破能够对若干重大挑战都带来进展。
现在待处理的推荐系统规模越来越大,用户和商品(也包括其他物品,譬如音乐、网页、文献……)数目动辄百千万计,两个用户之间选择的重叠非常少。如果用用户和商品之间已有的选择关系占所有可能存在的选择关系的比例来衡量系统的稀疏性,那么我们平时研究最多的MovieLens数据集的稀疏度是4.5%,Netflix是1.2%。这些其实都是非常密的数据了,Bibsonomy是0.35%,Delicious是0.046%。想想淘宝上号称有近10亿商品,平均而言一个用户能浏览1000件吗,估计不能,所以稀疏度应该在百万分之一或以下的量级。数据非常稀疏,使得绝大部分基于关联分析的算法(譬如协同过滤)效果都不好。这种情况下,通过珍贵的选择数据让用户和用户,商品和商品之间产生关联的重要性,往往要比用户之间对商品打分的相关性还重要。举个例子来说,你注意到一个用户看了一部鬼**,这就很大程度上暴露了用户的兴趣,并且使其和很多其他看过同样**子的用户关联起来了——至于他给这个**子评价高还是低,反而不那么重要了。事实上,我们最近的分析显示,稀疏数据情况下给同一个商品分别打负分(低评价)和打正分的两个用户要看做正相关的而非负相关的,就是说负分扮演了“正面的角色”——我们需要很严肃地重新审查负分的作用,有的时候负分甚至作用大于正分。
这个问题本质上是无法完全克服的,但是有很多办法,可以在相当程度上缓解这个问题。首先可以通过扩散的算法,从原来的一阶关联(两个用户有多少相似打分或者共同购买的商品)到二阶甚至更高阶的关联,甚至通过迭代寻优的方法,考虑全局信息导致的关联。这些方法共同的缺点是建立在相似性本身可以传播的假设上,并且计算量往往比较大。其次在分辨率非常高的精度下,例如考虑单品,数据可能非常稀疏。但是如果把这些商品信息粗粒化,譬如只考虑一个个的品类,数据就**立刻变得稠密。如果能够计算品类之间的相似性,就可以帮助进行基于品类的推荐(图2是品类树的示意图)。在语义树方面有过一些这方面的尝试,但是很不成熟,要应用到商品推荐上还需要**和技术上的进步。另外,还可以通过添加一些缺省的打分或选择,提高相似性的分辨率,从而提高算法的精确度。这种添加既可以是随机的,也可能来自于特定的预测算法。
随机的缺省分或随机选择为什么**起到正面的作用呢,仅仅是因为提高了数据的密度吗?我认为仔细的思考**否决这个结论。对于局部热传导的算法,添加随机连接能够整体把度最小的一些节点的度提高,从而降低小度节点之间度差异的比例(原来度为1的节点和度为3的节点度值相差2倍,现在都加上2,度为3的节点和度为5的节点度值相差还不到1倍),这在某种程度上可以克服局部热传导过度倾向于推荐最小度节点的缺陷。类似地,随机链接可以克服协同过滤或局部能量扩散算法过度倾向于推荐最大度节点的缺陷。总之,如果拉小度的比例差异能够在某种程度上克服算法的缺陷,那么使用随机缺省打分就能起到提高精确度的作用。
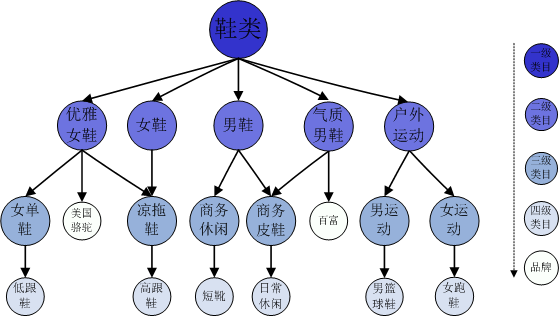
图2:品类树的示意图
新用户因为罕有可以利用的行为信息,很难给出精确的推荐。反过来,新商品由于被选择次数很少,也难以找到合适的办法推荐给用户——这就是所谓的冷启动问题。如果我们能够获得商品充分的文本信息并据此计算商品之间的相似性,就可以很好解决冷启动的问题,譬如我们一般不担心图书或者论文推荐**遇到冷启动的问题。不幸的是,大部分商品不同于图书和文章本身就是丰富的内容,在这种情况下通过人工或者自动搜索爬取的方法商品相应的描述,也**有一定的效果。与之相似,通过注册以及询问得知一些用户的属性信息,譬如年龄、居住城市、受教育程度、性别、职业等等,能够得到用户之间属性的相似度,从而提高冷启动时候推荐的精确度。
最近标签系统(tagging systems)的广泛应用提供了解决冷启动问题的可能方案。因为标签既可以看作是商品内容的萃取,同时也反映了用户的个性化喜好——譬如对《桃姐》这部电影,有的人打上标签“伦理”,有的人打上标签“刘德华”,两个人看的电影一样,但是兴趣点可能不尽相同。当然,利用标签也只能是提高有少量行为的用户的推荐准确性,对于纯粹的冷启动用户,是没有帮助的,因为这些人还没有打过任何标签。系统也可以给商品打上标签,但是这里面没有个性化的因素,效果**打一个折扣。从这个意义上讲,利用标签进行推荐、激励用户打标签以及引导用户选择合适的标签,都非常重要。
要缓解冷启动的问题,一种有效的办法是尽可能快地了解用户的特点和需求,所以如何设计问卷调查本身以及如何利用其中的信息也是一门大学问。与之相对应,对于一个新商品,怎么样让用户,特别是有影响力的用户,对其给出高质量的评价,对于解决冷启动问题也有重大价值。如何在保证一定推荐精度的情况下,让新用户和新商品的特性尽快暴露,是一个很有意义也很困难的研究难题。
最近一个有趣的研究显示,新用户更容易选择特别流行的商品——这无论如何是一个好消息,说明使用热销榜也能获得不错的结果。冷启动问题还可以通过多维数据的交叉推荐和社**推荐的方法部分解决,其精确度和多样性又远胜于热销榜,这一点我们在后面**进一步介绍。
未完待续:个性化推荐十大挑战(中)
本文来源:产品中国
