时间: 2021-07-30 10:12:40 人气: 1 评论: 0
本文介绍了设计好的AI用户体验时需要牢记的三个基本原则——期望、错误和信任。

在先前的文章,我谈到了《AI 开发指南:机器学习产品是什么?》,AI及ML产品需要更多的试验、反复调整,也因此带来更多的不确定性。 关于什么是AI及ML产品,在《如何设计和管理AI产品?》这篇文章里有更详细的说明。
因此,我们需要为ML工程师和数据科学家提供足够的空间和弹性,来探索可能的解决方案。 同时也需要明确定义目标函数(objective function),并鼓励团队尽早测试,以免失去方向。
为AI&ML 产品设计用户体验 (UX) 时,同样面临这样的挑战。 在过去的几个月里,我与UX团队合作,收集客户意见并改进ML产品的用户体验。 以下是我们学到的三件最重要的事情:
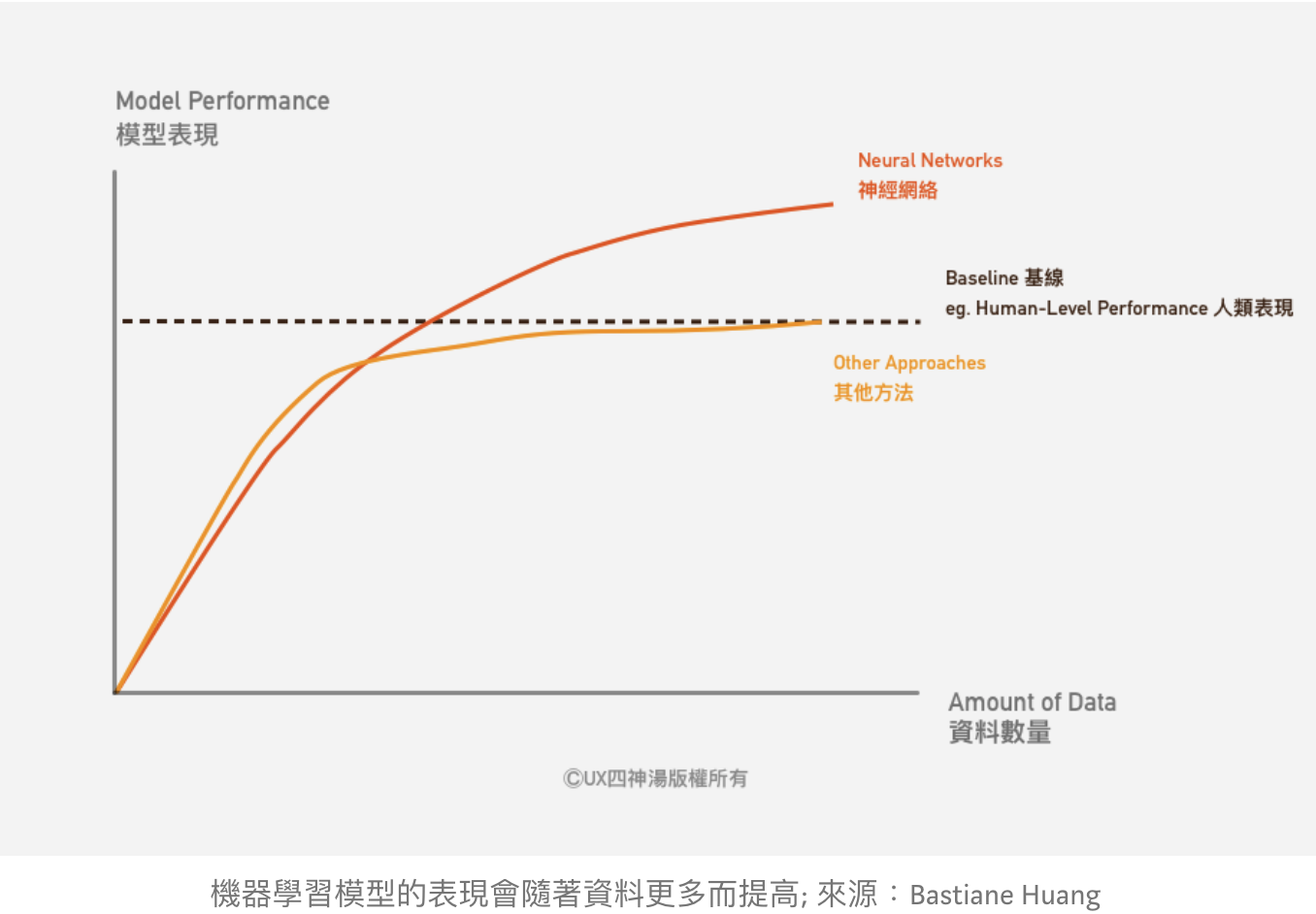
机器学习模型的表现**随着数据更多而提高,也就是说,ML模型**不断自我进步,这是使用AI&ML最大的好处之一。 但这也意味着,他们一开始的表现不**是完美的。
因此,必须让用户了解ML产品不断进步的本质。 更重要的是,我们需要与用户合作,事先确定一套验收标准(acceptance criteria)。 只有当ML模型符合验收标准时,我们才**推出该项产品。
设置验收标准时,可以比较系统的基准性能(baseline performane),替代或现有解决方案的性能,或甚至是比较标准答案(ground truth),
例如:比较人工翻译及机器翻译的准确度。 或是将机器预测的天气数据,拿来与真实天气数据做比较。 又或是将机器包装的速度及准确度,与人工操作比较,客户可以设定:唯有ML模型的准确度到达人工的90%才能上线。
有时,制定验收标准可能比想象中复杂:你可能有多个不同的用户类型,他们需要不同的验收标准。 或者,你的使用案例要求在某个特殊项目必须完全没有错误。
另外需要注意的是,模型本身的准确性通常并不是最好的衡量标准,一般需要考虑精确度(Precision)和召回率(Recall)之间的权衡。 这在前一篇文章有更详细的说明。
如果用户需要ML模型从第一天开始就有很好的表现,可以预先训练的模型(pretrained model):是先搜集数据,确定模型达到验收标准。
但是,要注意的是,即使使用预先训练的模型,例外情况(edge case)仍可能发生。 你需要与用户合作,制定计划降低风险。例如:如果模型不起作用,有什么备案? 如果用户想要添加新的使用案例,需要多长时间重新训练模型? 需要多少额外的数据? 当不允许更新模型时,用户是否可以设置更新中断期? 这些问题都需要事先回答。
通过建立用户的正确期望,你不仅可以避免用户挫折,甚至可以让用户感到惊喜。 亚马逊搭载Alexa语音助理的智能型喇叭就是一个很好的例子。 我们对类人形机器人有很高的期望:我们预期它们可以像人类一样自然交谈和动作。
所以,当智能机器人Pepper(下图)没有办法和我们进行流畅的对话时,我们感到沮丧,不想再使用它。 相比之下,Alexa 定位为智能型喇叭,降低了客户的期望。 当我们了解到它不仅仅可以播放音乐,还有很多其他的功能时,就能够让用户感到预期外的惊喜。
保持信息公开透明(transparency)是加强沟通和信任的另一个重要部分。 ML 比软件工程更具不确定性。 因此,显示每个预测的信赖区间(confidence level),也是建立正确期望的一种方式。 这么做也能够让用户更了解算法的工作原理,从而与用户建立信任。
ML算法通常缺乏透明度,就像一个黑盒子,我们知道输入(例如图像),和输出预测(例如,图像中的对象/人员是什么)分别是什么,但不知道盒子里是如何运作的。 因此,向用户解释ML模型如何运作很重要,可以帮助我们建立信任,和获得用户支持。
如果不对算法多做说明,有可能**让用户感觉被疏远,或感觉产品不够人性化。 例如,优步司机抱怨说Uber算法感觉非人性化,他们质疑算法的公平性, 因为算法所做的决定,并没有给他们明确的解释。 这些驾驶也认为算法搜集很多他们的数据,对它们非常了解,但他们对算法的工作原理和决策却了解的很少。
相反的,亚马逊的网页很清楚地告诉用户为什么他们推荐这些书。 这只是一个简单的单行解释。 告诉用户其他看过该项产品的用户还浏览过什么商品,但却可以让用户大致了解算法的原理,让用户可以更好地信任推荐系统。

同样的优步司机研究也发现,司机觉得他们经常被监视,但他们不知道这些数据将用于什么用途。 除了遵守 GDPR 或其他数据保护法规外,还应该尝试让用户了解他们的数据是如何被管理的。
“… 也有未知的未知-那些我们不知道我们不知道的… 这一类往往是最困难的”
——唐纳德· 拉姆斯菲尔德
“… But there are also unknown unknowns — the ones we don’t know we don’t know… it is the latter category that tend to be the difficult ones”
——Donald Rumsfeld
在设计系统时,通常很难预测系统**如何出错。 这就是为什么用户测试和质量保证(Quality Assurance),对于识别失败状态(fail state)和例外情况(edge case)极其重要。 在实验室或实际现场,进行更多的测试,有助于最大限度地减少这些错误。
你也需要根据错误的严重性和频率进行分类和处理。 有需要通知用户并立即处理的致命错误(fatal error)。 但也有一些小错误,并没有真正影响系统的整体运作。 如果你每个小错误都通知用户,那**非常烦人,干扰用户的产品体验。 相反的,如果不立即解决致命错误,那可能**是灾难性的。
你可以将错误视为用户期望和系统假设之间预期之外的交互(unexpected interactions between user expectations and system assumptions):
举例来说,如果用户不断拒绝来自App应用的建议,产品团队可能需要查看并了解原因。 例如,用户可能从日本搬到了美国,但是应用程序错误地根据用户的日本信用卡信息,假设用户居住在亚洲。 在这种情况下,用户的实际位置数据可能是提出此类建议的更好数据依据。
最棘手的错误类型是未知未知(the unknown unknowns):系统无法检测到的错误。 像上面的例子就是属于这种错误类型,必须要回去分析数据或异常模式,才有可能察觉。
另一种方法是允许用户提供回馈feedback:让用户能够很容易地,随时随地提供回馈。 让用户帮助你发现未知未知,或是其他类型的错误。
你也可以利用用户回馈来改进你的系统。 例如。 YouTube 允许用户告诉系统他们不想看到的某些建议。 它还利用这一点收集更多数据,使其建议更加个人化和准确。


将ML模型预测作为建议,而不强制用户执行,也是管理用户期望的一种方式。 你可以为用户提供多个选项,而不指定用户应执行哪些操作。 但请注意,如果用户没有足够的信息来做出正确的决策,这个方法就不适用。
我们之前谈到的许多一般原则仍然适用在这里。 你可以在我上一篇文章中找到更多详细信息。
作者:Bastiane Huang,拥有近10年产品及市场开发管理经验,目前在旧金山担任 AI/Robotics新创公司产品经理,专注于开发机器学习软件,用于机器人视觉和控制。
本文由 @Bastiane 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash,基于 CC0 协议。
