时间: 2021-07-30 11:00:06 人气: 14 评论: 0

本文原作者 Matthew Coffman,他是专注于企业云的风投基金 High Alpha 的产品经理,具有丰富的大数据行业经验,也参与和见证了许多数据类公司的创立和发展。根据自己在行业里多年的观察和思考,Matthew Coffman 提出了以下几条针对初创公司的数据科学实践指南。
首先,我们需要明确一个概念:什么是数据科学家?
一般的定义是:能够采用科学方法、运用数据挖掘工具对复杂多量的信息进行数字化重现与认识,并能从中找出新的数据洞察的工程师或专家。这里,从实际工程的角度,来自知名信息聚合平台 Slack 的首席数据工程师 Josh Wills 对数据科学家下了这样一个更精辟的定义:软件工程师里统计学最好的,统计学家里编程能力最强的那些人,就是数据科学家。
下面进入正题,作为一个初创公司的项目主管,怎样才能更好地应对数据科学挑战呢,有如下几条实践指导。
首先需要明确的一点是,当前的数据科学、机器学习和 AI 作为一个独立的行业都已经具备了相当的体量。利用各种供应商提供的各种平台、工具和算法,我们几乎可以解决所有应用程序的相关问题。
但这些工具和平台,与真正的数据科学家是两回事。事实上,目前所有的大公司都在竞聘行业里顶尖的数据科学家。因此,对于那些专注于研究下一代的智能聊天机器人或者大数据分析应用的创业者来说,机**已经不多了。
如果你的公司足够幸运,已经招到了一位珍贵的数据科学家,那就一定要让他作为你的合伙人,共同规划和执行公司的项目。同时你需要明确的一点是,在构建和扩展应用程序的所有其他复杂功能方面,数据科学家们很多时候并不具备其他工程师的专业知识和经验。一定要让数据科学家和工程师协同合作,共同参与项目的规划,才能最大限度地确保成功。
那么,在缺少主题专家的情况下,项目主管要怎样为其产品寻求有意义的数据科学驱动功能呢?这里推荐一个非常实用的方法:就像大多数其他产品的规划流程一样,做到理智的取舍。在当前丰富而强大的工具和平台的帮助下,团队可以实现几乎任何想要的功能。因此,对项目主管来说,重点就在于确定真正核心的功能并平衡其影响。
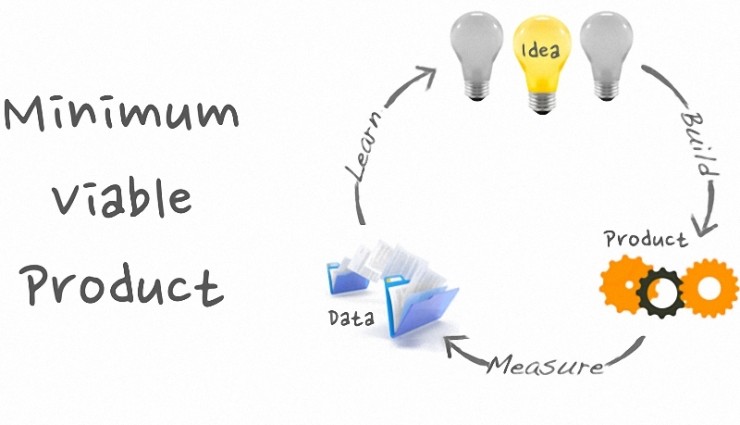
创业圈流行这样一个理念:开发产品时先做出一个简单的原型——最小化的可用产品(Minimum Viable Product, MVP),然后通过测试并收集用户的反馈,快速迭代,不断修正产品,最终适应市场的需求,推出让用户满意的产品。这一点放在数据产品上也同样适用。
要做到 MVDP,有以下三点需要注意:
项目主管可以从产品特性讨论开始,优先考虑那些对客户最有价值的特性。并且与工程师团队(以及潜在的数据科学专业人员)一起讨论,确定待实现的特性与现有的数据、资源是否匹配。
不要担心缩小范畴,MVDP 本身的目标就是快速输出一个对客户有价值的原型产品。只要能证明这个原型有价值,后续可以再添加额外的复杂功能。这一点放在数据科学项目上尤其重要,因为数据产品在很大程度上就是要尽量防止过多的复杂性,以减少项目落空的机**。
当前,一般的工程师和产品团队在实现产品性能方面都表现优异,但是他们通常都需要一些工具包或者框架的帮助。数据科学家们提供了给定数据集的深层次的理解,提供了正确的工具/技术来帮助实现产品特性,并成功将这些工具和产品应用到产品研发的过程中。可能有些创业公司目前并没有自己的数据科学家,但可喜的是,现在互联网上充满了相关教程和学习资料,还有丰富的程序Demo和API接口,可以帮助这些公司实现数据科学的相关功能。
而且,目前几乎所有的算法和技术都可以找到第三方实现好的现成的工具包,工程师团队真正的研发重点应该是数据的准备和加载,训练和选择合适的模型/算法/工具,并将其成功应用在产品里。必须明确的一点是:团队不应该完全从零开始构建所有东西,这是一种宝贵资源的浪费。
随着 MVDP 的实现,下面需要找到最实用的方法来实现产品特性。当然,需要首先明确的一点是:并不存在某个单一的工具或平台适合所有产品。对此,我们给出以下几条建议。
1. 通用的机器学习平台和预测服务:Google Prediction API,Amazon Machine Learning API,Microsoft Azure Machine Learning API 以及 BigML。通过这些开放 API 接口,用户可以将数据输入到预先构建好的或者自定义的模型,实现快速测试,并合并到产品中。这种类型的服务非常适合于预测用户行为,在大数据集中标记用户和产品,以及对数据集进行优先级排序等场景。

2. 特定用途的 AI 平台:这一类的工具似乎发展势头强劲,初创公司可以直接接入这些平台,然后通过云端计算实现各种各样的创新功能。主要的供应商包括 IBM Watson(语音识别,图像识别,翻译)和 Google Cloud(语音,文字,图像和其他服务),并且每天都有许多这一类的新兴的初创公司涌现。
3. 博客,资源和社区讨论:与大多数其他领域的发展一样,互联网提供了一个分享**的基础,初创公司可以相对容易地与其他团队分享和交流他们的数据科学项目经验,并相互学习,取长补短。这里建议 KDnuggets 和 O’Reilly 这两个社区。
这里还需要强调:无论借助哪种工具或者框架的帮助,项目主管都需要明确:始终聚焦于向客户提供有价值的最小化的可行产品,然后其他所有的各项措施都是围绕这一核心目标展开的。明确这一点,有助于保持数据科学的相关项目始终在可控的范围内成长。
在做任何一个特性之前,都需要首先明确如何衡量客户对该特性的满意度。考虑到数据科学项目额外的复杂性,因此,在客户反馈和特性迭代之间建立一个紧密的循环机制就变得更加重要。而且由于对数据和模型的巨大依赖,因此通常情况下研发人员很难排查为什么最终实现的特性没有预想的效果好。另外,项目主管在制定每一轮迭代的预期工作量时都发挥着至关重要的作用,并且通常还需要针对一些计划外的工作价值做出判断。在某些极端的情况下,如果一个特性看起来需要太多的工作投入或者结果仍然不可预测,那么就有可能选择完全放弃该特性。
值得注意的是:一个好的项目主管应该在客户和数据之间保持一种勤奋的工作关系。当客户实测一个数据科学驱动的新特性时,及时准确地考察来自这两个来源的反馈将变得至关重要。
Slack的首席数据工程师 Josh Wills 表示:当前对许多公司而言,数据科学方面的投入只是其众多产品投入的一部分。在大多是情况下,只需要一项或者两项的投入起作用,就能支撑起整个产品。而且,数据科学的入门真的很难,他称之为信仰的行为(an act of faith)。像Facebook、谷歌和亚马逊这样的巨头公司,他们的发展规模其实早已**出了建立时的初衷,数据科学几乎变成了所有业务的核心驱动力。现在,机器学习和数据科学几乎变成了所有大公司用来创造价值的主要工具,他们通过考察用户体验掌握先机,然后通过自动化的方法通过特定的产品使客户的生活变得越来越便捷。
从实用的观点来说,当下的项目主管应该要开始尝试将数据科学的相关特性融入到产品中去。虽然赶**大公司可能仍然是一个不小的挑战,但我们需要聚焦于我们自己的目标客户的实际需求,并尽一切可能的努力去提升他们的使用体验。
译者:恒亮
作者:Matthew Coffman
来源:http://www.leiphone.com/news/201703/ma4y2LGXMUk6Ncgh.html
本文来源于人人都是产品经理合作媒体@雷锋网,作者@Matthew Coffman
