时间: 2021-07-30 11:00:06 人气: 15 评论: 0

文章分享了一种挖掘潜在用户的算法,与大家分享,希望可以給大家带来启发。
你是否收到过促销短信?
你是否在打开APP时发现有商家推送优惠消息?
这只是简单的群发么?当然不是。
你在网站上的所有行为,代表着你的意向和需求,所以通过算法,网站就能把你推送给相应店家。
你以为网站靠卖卖卖赚钱,对没错,卖的就是你。
这只是个玩笑,接下来要讲的是,玩笑背后的真实买卖——如何挖掘潜在用户。
区别于“猜你喜欢”:发现用户是帮助B端客户挖掘潜客;猜你喜欢是帮助用户更了解自己的需求。以淘宝为例,为用户推送她关注的红色连衣裙,用推荐算法;那推荐哪个卖家的这条裙子呢,那就是要用到挖掘潜客了。
算法不同:猜你喜欢主要是相似度算法,潜客推荐主要是客观赋权和评分算法。
接下来要介绍的发现潜客算法:
全网用户的所有行为:为了更好地说明,简化为浏览、收藏、在线咨询这三种行为。
这里涉及到一个概念“差异驱动”:当评价对象在某一指标的差异越大时,我们认为这个评价指标的重要性越大。
所以,这三种行为代表用户购买意愿由弱到强。
第一步:计算行为的出现概率
首先,通过近一个月的用户行为数据,算出浏览、收藏、在线咨询这三种行为出现的概率,依次记做P’1、P’2、P’3,假设计算结果为70%、20%、10%。
第二步:为不同行为客观赋权
我们需要利用信息熵来对行为客观赋权。主观上,也可以自定义权重,当然也能根据上一步的概率来赋权,但为了更精确地进行用户评分,需要用特定算法来处理。
首先,信息熵计算
信息熵是衡量一个系统的有序化程度,熵越大表示信息无序化程度越高,信息效用越低。比如球场上一方胜率为70%另一方30%,比两方胜率不明确(均为50%)的熵要小,胜率越明确信息越有效。
其原理可参考论文《利用信息熵计算评价指标权重原理及实例》,作者罗进。
信息熵由信息论之父Shannon提出 ,公式为:
![]()
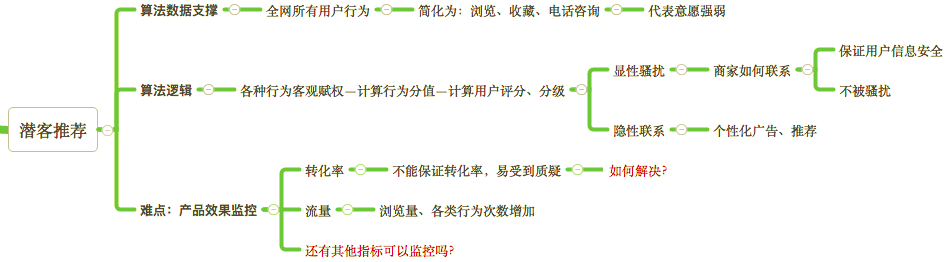
这里的Pi就是代表某一行为的概率,该公式是正相关的关系,但本文中“用户行为的P’i越小表示行为越重要,故权重越小”,为了纠正变量之间的关系,取其倒数Pi=1/P’i,这样才符合我们需求——变量负相关。
接着,数据归一化处理
由于不同行为的性质不同,如果直接用原始值进行对比,就**突出数值较高的指标在综合分析中的作用,同时弱化数值较低的指标的作用,从而使各指标以不等权参加运算分析。为避免这一点,**对数据进行无量纲化处理,也称归一化。算法多样化,一般是算出标准差或极值来作为归一化的系数,记做C。
具体计算方法和原理可参考:http://www.docin.com/p-674202391.html
最后,行为权重计算
加入归一化系数,使权重统一化,公式为:
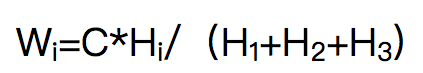
第三步:行为分值确定
给每种行为分配分值:
设浏览行为的分值为T1,则收藏T2=T1*(W2/W1),电话咨询T3=T1*(W3/W1)
第四步:用户评分
小明今天浏览、收藏、电话咨询的次数记为a、b、c,那么其分数为:
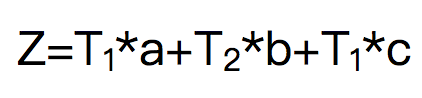
首先,此算法可以有多种变种。如果要做得更圆满,应该还要考虑权重的时间变化(比如永远以最近30天的行为来计算概率)、加入用户的消极行为(取关、投诉、差评)、用户习惯(购买周期、页面停留时间等)、用户现状(已购哪些、已退哪些、收藏哪些)等完善用户画像。
其次,行为赋权有什么用?用户评分可以怎么用?对B端来说,可以对这些用户进行进一步分级,不同级别分别可以电话联系、发短信、IM聊天或消息推送,当然更潜移默化的方式是个性化广告展示、猜你喜欢展示、消息精准推送。对普通用户来说,用户评分是用来满足和挖掘他们的需求,对不同分值的用户提供个性化服务、分层次的权益、针对性的产品。
最后,如何进行效果监控评估?算法的价值在于用得好,不在于专业或者复杂度。能否提升转化率、增加流量、满足用户需求,都需要恰当地配合恰到好处的服务,见仁见智。
欢迎补充和提问。
全文完。
作者:小乔,公众号:乱入花间化绿叶。产品小白一枚,希望通过这种每周一次深入思考总结的方式,促进自己的成长,走出从0到1到无穷的产品之路。
本文由 @小乔 原创发布于人人都是产品经理。未经许可,禁止转载。
