时间: 2021-08-03 09:38:01 人气: 13 评论: 0

我不知道技术是否有罪,我只知道,这些**踞在我们广袤版图上数以十亿计的爬虫,无时无刻不在提醒着我们:抱怨不**让这个世界变得更好,你想生活在一个怎样的世界,就要用自己的双手去创造它。
这里有三个问题:
每年总有那么几天,幺哥**心情焦虑,坐立不安。那是因为,他又要准备抢回家的火车票了。幺哥家在湖南,离北京上千公里。他是家里的独子,每年买到火车票准时出现在家门口是他的“义务”。
这两年,他的救命稻草是一个抢票软件,他在打折的时候买了**,据说**是有特权的:哪怕只抢到一张票,都**优先给他。(起码幺哥是这样安慰自己的。)
从技术上说,幺哥的救命稻草不是抢票软件,而是抢票软件背后,无数个叫做“爬虫”的东西。
爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来,就像一只虫子在一幢楼里不知疲倦地爬来爬去。
你每天使用的百度,其实就是利用了这种爬虫技术:每天放出无数爬虫到各个网站,把他们的信息抓回来,然后化好淡妆排着小队等你来检索。抢票软件,也相当于撒出去无数个分身,每一个分身都帮助你不断**新 12306 网站的火车余票。
正好在上周末,一位黑客盆友御风神秘兮兮地给我发来一份《中国爬虫图鉴》,这哥们在某安全实验室主要负责加班,顺便和同事们开发了很多黑科技。比如:他们搞了一个威胁情报系统,号称能探测到全世界的“爬虫”都在做什么。
我打开《图鉴》,一分钟以后,我整个人都不好了,我看到了另一个“平行世界”:
就在我们身边的网络上,已经密密麻麻爬满了各种网络爬虫,它们善恶不同,各怀心思。而越是每个人切身利益所在的地方,就越是爬满了爬虫。看到最后,我发现这哪里是《中国爬虫图鉴》,这分明是一份《中国焦虑图鉴》。

我们今天要说的,就和这些 App 有关。
爬虫也分善恶。像谷歌这样的搜索引擎爬虫,每隔几天对全网的网页扫一遍,供大家查阅,各个被扫的网站大都很开心。这种就被定义为“善意爬虫”。
但是,像抢票软件这样的爬虫,对着 12306 每秒钟恨不得撸几万次,铁总并不觉得很开心,这种就被定义为“恶意爬虫”。(注意:抢票的你觉得开心没用,被扫描的网站觉得不开心,它就是恶意的。)
给你看一张图:
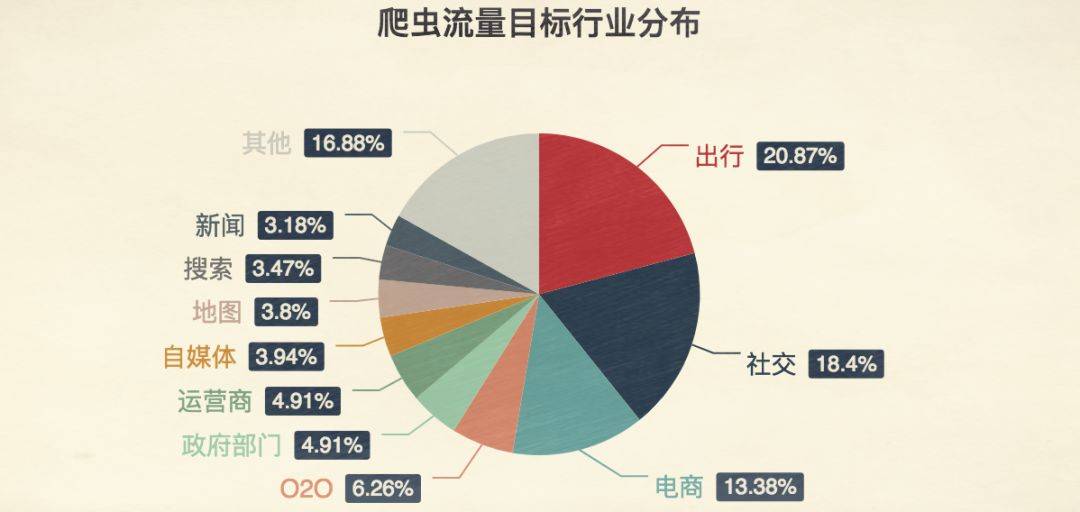
这张图里显示的,就是各行各业被爬“叨扰”的比例。(这张图显示是全世界,不是全中国)而每一个色块背后,都是一条真实而强大的利益链条。
出行行业中爬虫的占比最高(20.87%),在出行的爬虫中,有89.02%的流量都是冲着 12306 去的。这不意外,全中国卖火车票的独此一家别无分号。
你还记得当年12306 上线王珞丹和白百何的“史上最坑图**验证码”么?
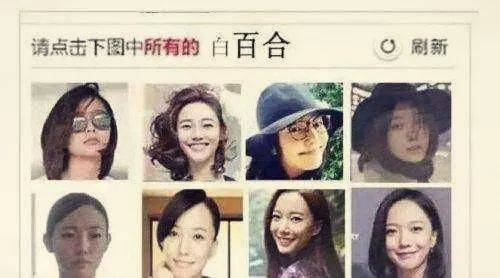
这些东西不是为了故意难为老老实实卖票的人的,而恰恰是为了阻止爬虫(也就是抢票软件)的点击。刚才说了,爬虫只**简单的机械点击,它不认识白百何,所以很大一部分爬虫就被挡在了门外。
你可能**说,不对啊,我现在还可以用抢票软件抢到票啊。
没错,抢票软件也不是吃素的,它们在和铁总搞“对抗”,有一种东西叫做“打码平台”,你可以了解一下。
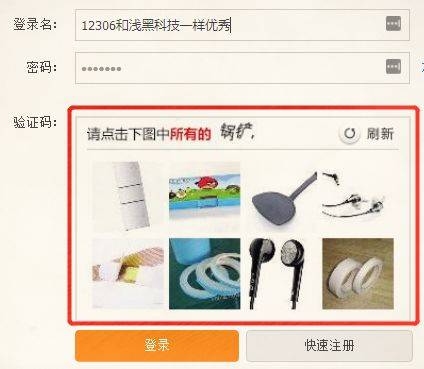
打码平台雇佣了很多叔叔阿姨,他们在电脑屏幕前不做别的事情,专门帮人识别验证码。那边抢票软件遇到了验证码,系统就**自动把这些验证码传到叔叔阿姨面前,他们手工选好哪个是白百何哪个是王珞丹,然后再把结果传回去。总共的过程用不了几秒时间。
这样的打码平台还有记忆功能,如果叔叔阿姨已经标记了这张图是“锅铲”,那么下次这张图**再出现的时候,系统就直接判断它是“锅铲”。时间一长,12306 系统里的图**就被标记完了,机器自己都能认识。
你可能**问:为什么 12306 这么“抠”呢?它大方地让爬虫随意爬**死吗?
**死。
你知道每年过年之前,12306 被点成什么样了吗?
公开数据是这么说的:
“最高峰时1天内页面浏览量达 813.4 亿次,1 小时最高点击量 59.3 亿次,平均每秒 164.8 万次。”
这还是加上验证码防护之后的数据,可想而知被拦截在外面的爬虫还有多少。铁路被爬虫“点鸡”成这样已经够惨了,但它还有个难兄难弟,就是航空。航空软件里,被搞得最惨的不是国航,不是海航也不是东航,而是亚航。
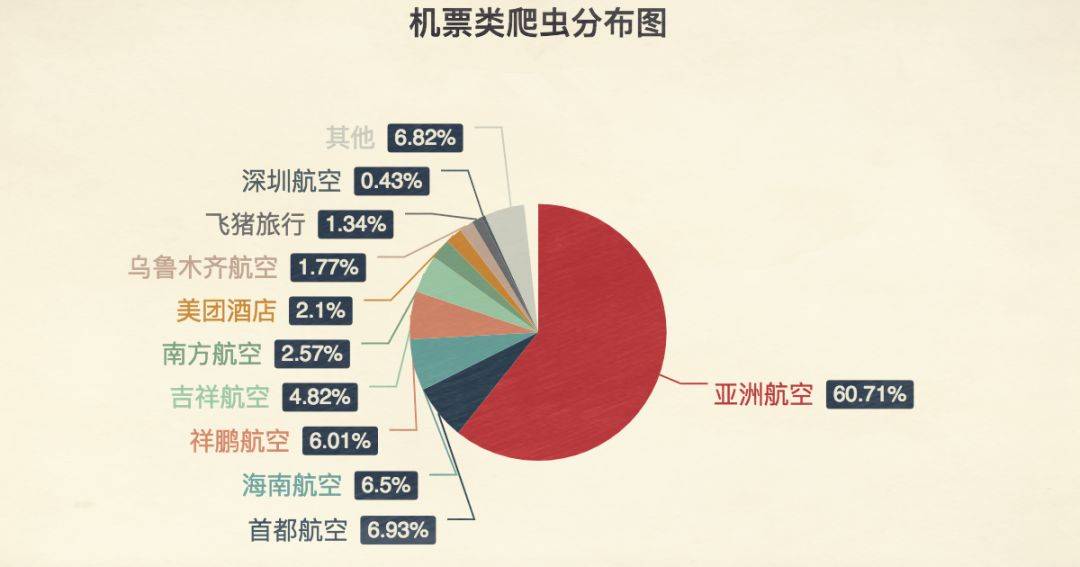
航空类爬虫的分布比例
很多人可能都没坐过亚洲航空,这是一家马来西亚的廉价航空公司,航线基本都是从中国各地飞往东南亚的旅游胜地,飞机上连矿泉水都得自费买,是屌丝度假之首选。
为什么爬虫这么青睐亚航呢?
因为它便宜,确切地说,因为它经常放出便宜的票。本来,亚航的初衷只是随机放出一些便宜的票来吸引游客,但这里面**牛党是有利可图的。
据我所知,他们是这样玩的:
技术宅**牛党们利用爬虫,不断**新亚航的票务接口,一旦出现便宜的票,不管三七二十一先拍下来再说。
亚航有规定,你拍下来半小时(具体时间记不清了)不付款票就自动回到票池,继续卖。但是**牛党们在爬虫脚本里写好了精确的时间,到了半小时,一毫秒都不多,他又把票拍下来,如此循环。直到有人从**牛党这里定了这个票,**牛党就接着利用程序,在亚航系统里放弃这张票,然后0.00001秒之后,就帮你用你的名字预定了这张票。
社交的爬虫重灾区,就是你们喜闻乐见的微博。
给你看张图:
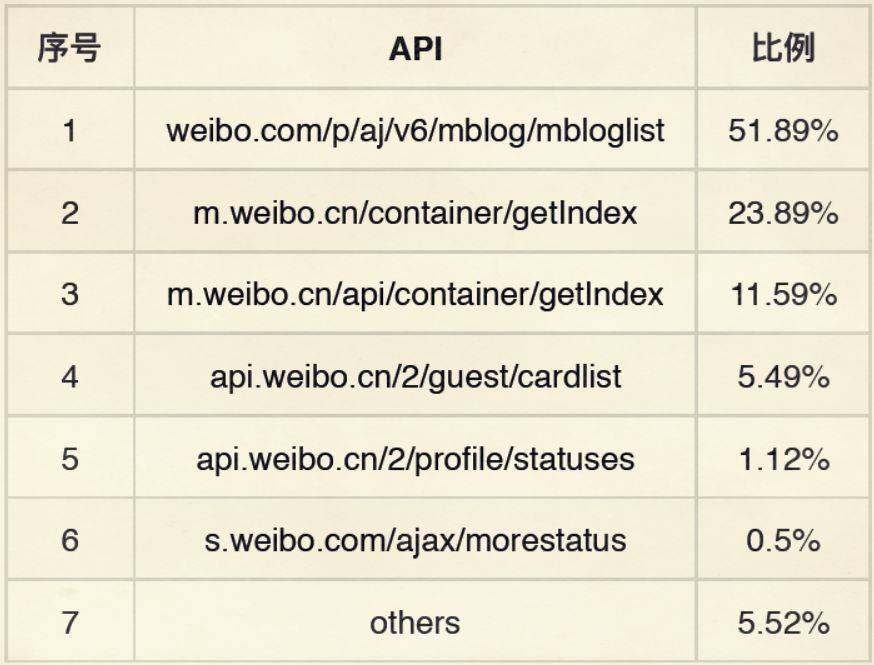
爬虫经常光顾的微博地址
这里的代码其实指向了微博的一个接口,它可以用来获取某个人的微博列表、微博的状态、索引等等。
获得这些,能搞出什么骚操作呢?
你想想看,如果我能随心所欲地指挥一帮机器人,打开某人的微博,然后**到某一条,然后疯狂关注、点**或者留言,这不就是标准的僵尸粉工作的流程么……
其实,僵尸粉都只是爬虫的常规操作,更骚的来了:
(以上数据不一定和现实吻合,只是展现一个逻辑。具体操作也**更复杂。)
同样的,十万僵尸粉去抢你家爱豆在微博上发的红包,都是一样的道理。
你回忆一下,有几种东西叫做“比价平台”、“聚合电商”和“返利平台”。
他们大体都是一个原理:你搜索一样商品,这类聚合平台就**自动把各个电商的商品,都放在你面前供你选择,如:淘宝、京东,还有唯品**苏宁易购。
这就是爬虫的功劳,它们去淘宝上,把不同网站的产品的图**和价格统统扒下来,然后在自己这里展示。

这个原理和谷歌差不多,只不过他们展示的不是网页而是商品。但是被放在一起比价,淘宝是拒绝的,京东也是拒绝的啊……
然而,由于机器爬虫模拟的是人的点击,电商很难阻止这类事情发生,他们甚至都不能向 12306 学习。你想想看,如果你每点开一个商品详情,淘宝都让你先分辨一次白百何和王珞丹,你肯定没心情剁手了。
当然,电商对抗爬虫有另外的方法,那就是“web 应用防火墙”,简称 WAF,这个我们后面再单独说。
说到这,有人**有个疑问:那些聚合平台,自己写爬虫,然后帮助淘宝京东卖货,他们的名字叫雷锋么?
醒醒啊同学,这里随便给你说一下这种聚合电商平台的盈利模式:
还记得开头我问的几个问题:你在大众点评上看到的信息,真是吃货们点评的吗?
答:大部分时候是,但有时候不是。这里面的影响因素还是爬虫。
御风告诉我,这些爬虫很可能被用来做两件事:
所以,**上讲一旦大众点评对这些爬虫对抗出现松懈,就**有一些并不怎么样的店铺被“**”到顶部。
与之相似的,是爬虫针对搜索引擎的进攻。
你可能了解,搜索引擎决定哪个网页排名靠前,(除了广告以外)主要一个指标就是看哪个搜索结果被人点击的次数更多。既然这样,那么我就派出爬虫,搜索某个特定的“关键词”,然后在结果里拼命地点击某个链接,那么这个网站在搜索引擎的权重里自然就**上升。这个过程就叫做 SEO(搜索引擎优化)。
举个例子:我随意搜索一个关键词。
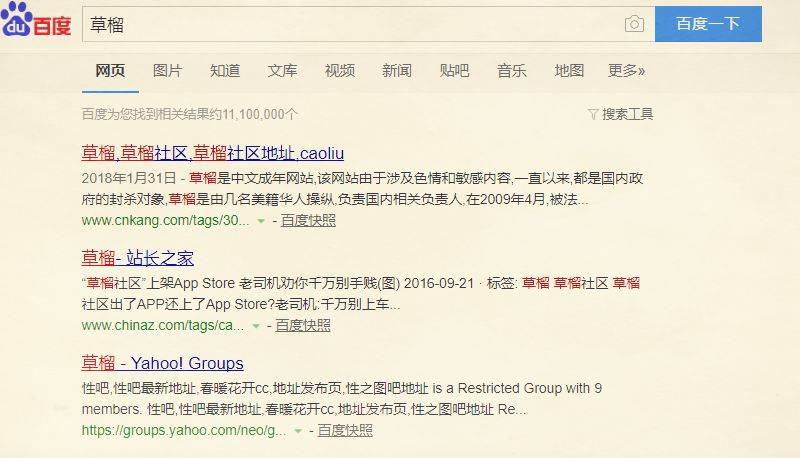
它排在前面的网址,有可能就是经过 SEO 的。作为任何一个搜索引擎,都肯定不允许外人对于自己的搜索结果动手动脚,否则就**丧失公立性。它们**通过不定期调整算法来对抗 SEO。
尤其是很多**、**色网站,搜索引擎如果敢收广告费让他们排到前面,那就离倒闭不远了。所以**网站只能利用黑色 SEO,强行把自己**到前面。直到被搜索引擎发现,赶紧对它们“降权”处理。不过御风算了算,这些**色网站如果能把自己**到前几位一两个小时,赚来的钱就远远**过 SEO 的费用。
你看这张图,全是爬虫针对政府信息的爬取。

第二名,北京市预约挂号统一平台,这个锅,板上钉钉要号贩子来背。
其他的,例如:法院公告、信用中国、信用安徽,为什么爬虫要爬这些信息呢?
因为有些信息,是只有政府部门才掌握的。
比如:谁被告过,哪家公司曾经被行政处罚,哪个人曾经进入了失信名单。这些信息综合起来,可以用来做一个公司或者个人的信誉记录。
我试着打开了一下排名第四位的“信用中国”。

在这个平台上,你只要输入一个身份证号或者手机号,就可以查询到一个人的信用情况,而这个网站正是属于政府机构的。

如果一家公司要对外做信誉库的服务,它必须先把信用中国的信息下载到自己的库里,然后才能和其他数据进行综合运算。如此,信用中国被爬,也就很容易解释了。
刚才那张表格里,排名第七的是四川住建厅。根据御风的推测,这很可能是某些公司提供的一项“特殊服务”:他们把四川省各个地区的招标情况汇总起来,然后实时提醒那些房地产公司“别睡了,起来投标了”。
说了这么多,我猜你**有几个疑问。
我打开中国网安第一大法《网络安全法》仔细看了半小时,在里面没有发现“爬取网络公开信息被认定为违法”的条款。
继续搜索,我又发现了几条司法解释:
未经授权爬取用户手机通讯录**过50条记录;未经授权抓取用户淘宝交易记录**过500条;未经授权读取用户运营商网站通话记录**过500条;未经授权读取用户公积金社保记录的**过50000条的。以上这些情况可以入刑。
但是仔细看看,如果我只是用机器代替了人的手点击鼠标敲击键**,接触的都是公开信息,并不触犯这些司法解释。(这只是我简单查询后的结果,不代表任何官方意见)
但是,对企业来说,爬虫却着实伤害了自己。有句话说:“主救自救者”,他们得组织“民兵”自己保卫自己。
爬虫和被爬企业越来越势不两立,说白了,他们的对抗都是在阻挡对方的财路,所以下手都挺重。
企业经典的对抗方式,大概有几种:图**验证码、滑块验证、封禁 IP、给访问者增加一些加解密运算,耗费爬虫的程序资源等等。
极验验证的滑块验证技术
除了刚才这些小模块,企业还可以通过 WAF(Web 应用防火墙)来防护,WAF 的功能就是通过设置一些规则,拦截掉那些不符合规则的请求。
但是,爬虫的请求,和真人的请求太像了。
我觉得,对这种战争一个形象的比喻就是抗癌。癌细胞的目的就是拼命躲过免疫细胞的识别,而免疫细胞的目标就是拼命分辨哪个是好细胞哪个是癌细胞。
在我看来,这场对抗爬虫的常规战眼看就要升级为“智能战”,而且战线**向云端转移。最近一些云安全厂商,已经在计划通过人工智能的方法来识别爬虫,主推反爬虫的技术。
不过,就像人类目前难以消灭癌症一样,企业也难以完全消灭爬虫。但是我相信,在对抗中这条战线**达到一个精妙的平衡。这个战线每向前推进一步,都需要安全研究员付出艰辛的努力。
最后,帮你搞到了一张表格,这是被监测到的受爬虫侵扰最多的 Top50。(采样数据,仅供参考)
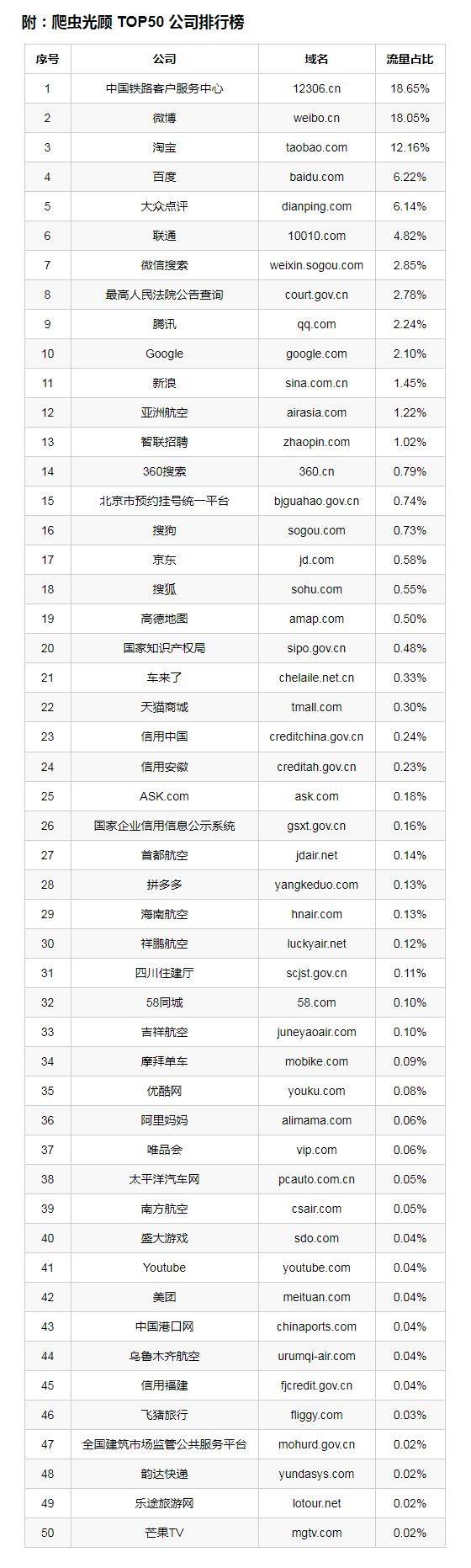
这张表里,除了google、Youtube、ask、亚洲航空这四家企业之外,应该全是中国企业(或机关)。正是从这些名字背后,我体**到了很多人的辛酸和焦虑。
爬虫是趋利的,它们永远**向有利益的地方爬行。而爬虫觉得有利益的地方,往往是我们不忍提及的隐痛。
排名第1的是“中国铁路路客户服务中心”,无数像幺哥一样的游子,他们奋斗在一个远离家乡的城市,为了让家人有更幸福的生活。正是他们难以买到过年回家车票的事实,才把 12306 推上了爬虫榜的第一名。
排名第8的是“最高人民法院公告查询”,在中国,我们的信用体系还很不完善,骗子和老赖还可以继续蒙骗新人。所以才催生了爬虫收集法院公告,形成民间信用记录的服务。
排名第15的是“北京市预约挂号统一平台”,我们的医疗改革在进行,但像你我一样的普通人仍然看病难,又便宜又好的医疗资源需要争夺,这才有了“一号难求”的现实,才有了**牛用爬虫拼命抢号的现象。
自不用说那些神坑的虚假广告,冲榜**量,背后都有爬虫的影子。
有人说技术有罪,有人说技术无罪。
我不知道技术是否有罪,我只知道,这些**踞在我们广袤版图上数以十亿计的爬虫,无时无刻不在提醒着我们:
抱怨不**让这个世界变得更好,你想生活在一个怎样的世界,就要用自己的双手去创造它。
作者:史中,是一个倾心故事的科技记者,微博:@史中方枪枪
原文链接:https://www.huxiu.com/article/254155.html
本文由 史中@浅黑科技 授权发布于人人都是产品经理,未经作者许可,禁止转载
题图作者提供
